# Extraction de documents PDF
L’objectif de ce module est d’extraire les informations de vos documents PDF via la configuration de traitements spécifiques. Les documents sont tout d’abord convertis au format html afin de profiter au maximum de ses possibilités pour cibler les éléments à récupérer comme la taille ou encore la police de caractères.
# Conversion des PDF en HTML en lot
Dans le cas où vous auriez de nombreux PDF à charger, il est possible de les télécharger et de les transformer en lot.
Étape 1 :
Allez sur l’onglet “Traitement” et sélectionner “Extraction pdf”. Télécharger les fichiers à traiter.
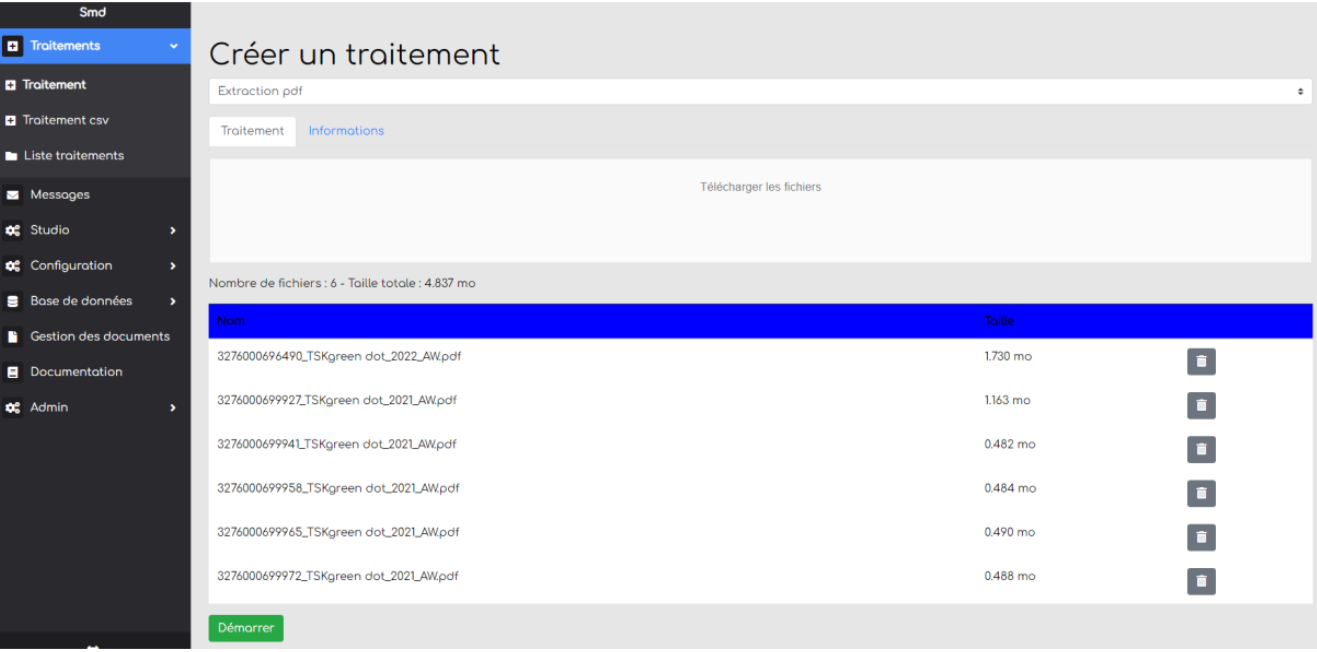
Étape 2 :
Les documents sont traités en lot. Si un document a déjà été traité auparavant, le traitement n’est pas relancé (la détection se fait au niveau du nom de fichier).
Les documents HTML sont enregistrés dans l’espace document.
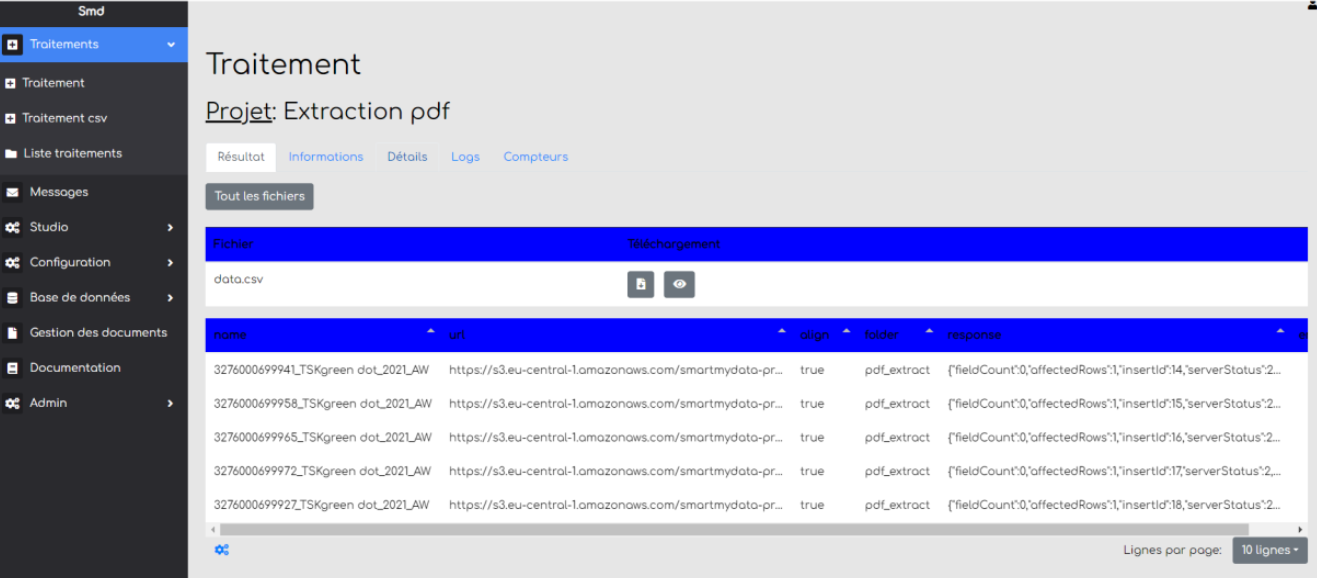
Étape 3 :
Dans l’onglet “Studio / Documents”, sélectionnez le fichier via le menu en bas, puis appuyer sur “+”.
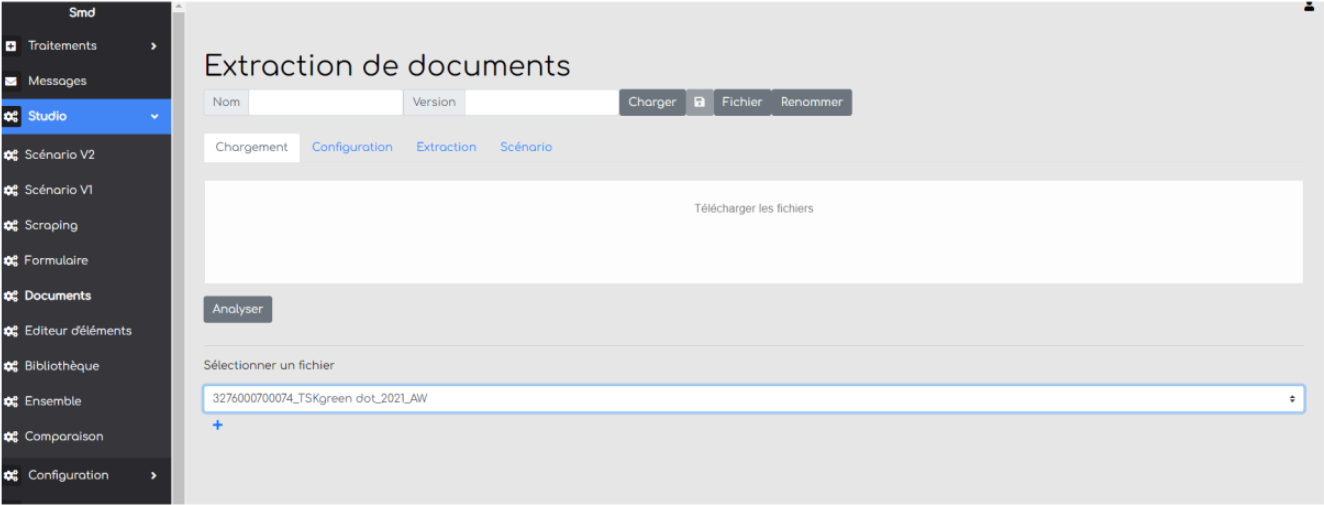
Étape 4 :
En passant dans l'onglet extraction, il est possible de commencer son paramétrage.

# Ouverture de l’espace scénario
Sélectionnez dans le menu de gauche “Studio” puis “Documents”.
# Ouvrir un scénario pré-existant
Cliquez sur le bouton “Charger”. Sélectionnez le nom et la version du scénario. Par défaut, la dernière version s’ouvre.
Le chargement du scénario charge également le document de référence ayant servi de base pour la création du scénario.
Le scénario se retrouve ensuite dans l’onglet “Extraction”.
# Copier un scénario
Chargez le scénario que vous souhaitez dupliquer, renommer le et enregistrer.

Renommage :

Enregistrez en cliquant sur  .
.
# Créer un scénario
# 1 - Charger un fichier
# 1.1 - Sans rotation
Onglet “Chargement”. Glissez/déposez un fichier dans l’encart “Télécharger les fichiers” ou cliquez dessus pour sélectionner le fichier voulu.
Une fois cela fait, cliquez sur le bouton “Analyser” pour transformer le fichier pdf en html. Cela peut être long pour les gros fichiers. N’hésitez pas à réduire leur taille pour gagner du temps avec des services comme celui-ci.
Document analysé :
# 1.2 - Avec rotation
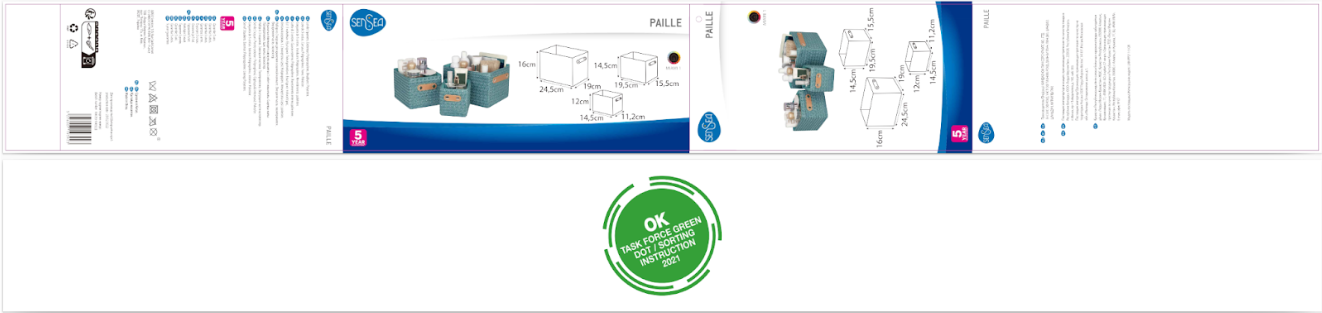
Ceci n’est utile que lorsque plusieurs pages d’un document pdf sont réunies en une seule avec des orientations différentes comme ici par exemple :
Rendez-vous sur l’onglet “Chargement”. Glissez/déposez un fichier dans l’encart “Télécharger les fichiers” ou cliquez dessus pour sélectionner le fichier voulu.
Puis rendez-vous sur l’onglet “Configuration”
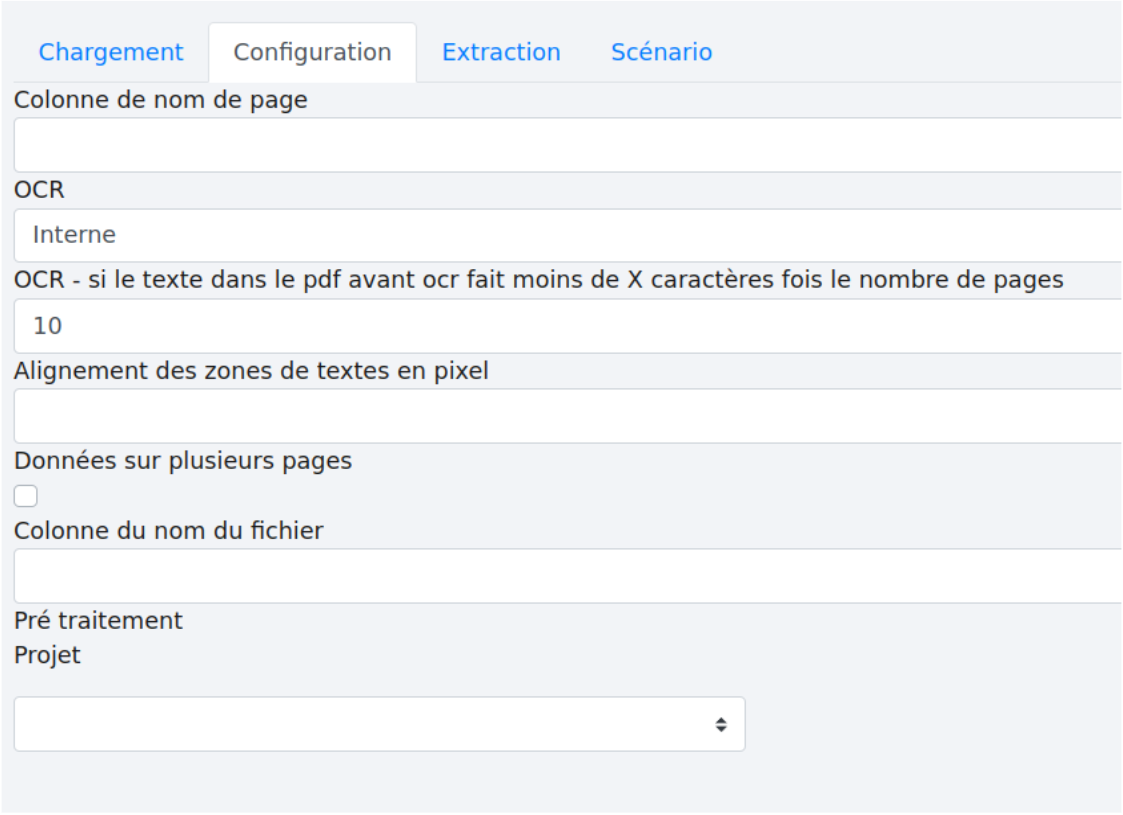
et sélectionnez le projet “Rotation” dans les “prétraitements”:

De nouveaux paramètres apparaissent alors. Il est possible d’effectuer jusqu’à deux rotations par fichier (contactez le support si vous en avez besoin de plus).
Cliquez sur  pour les faire apparaître.
pour les faire apparaître.
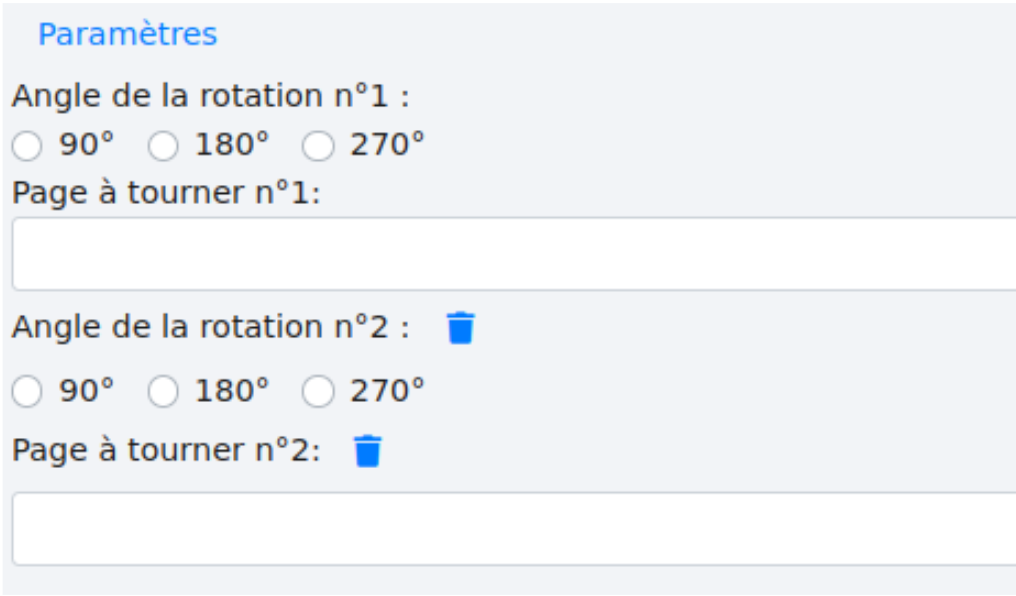
Dans l’exemple, la page 1 nécessite deux rotations pour les sections suivantes. Cette première section doit être tournée à 90° pour mettre les textes à l’horizontale.

Puis cette seconde section nécessite d’être tournée à 270°.

Ce qui donne les paramètres suivants :
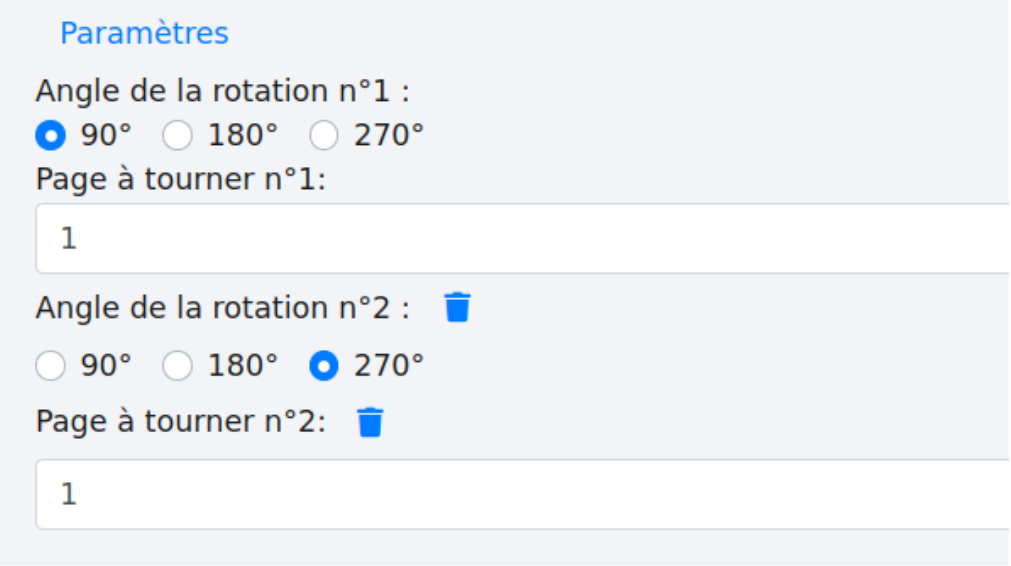
Il faut préciser l’angle de la rotation et le numéro de la page concernée. Les angles sont calculés dans le sens des aiguilles d’une montre.
Une fois le paramétrage réalisé, retournez sur l’onglet “Chargement” puis cliquez sur le bouton “Analyser”. Une fois l’analyse effectuée, allez sur l’onglet “Extraction”. Le menu déroulant des pages affiche non pas 2 mais 4 pages (les 2 de départ plus deux nouvelles correspondant à la page 1 tournée dans les deux sens précisés).

Votre document est prêt pour le paramétrage de l’extraction.
# 1.3 - OCR
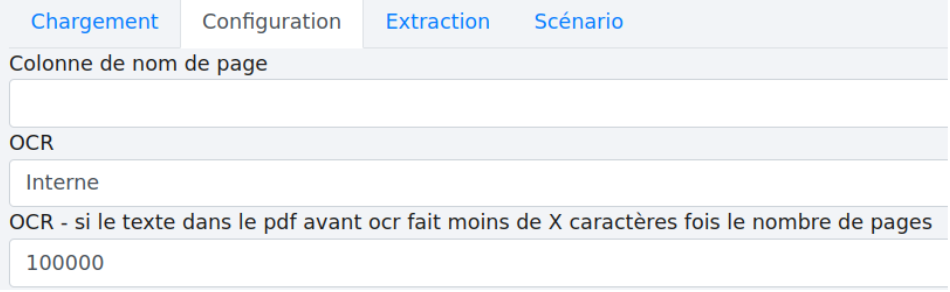
Si une partie seulement du document est reconnue, vous pouvez tenter de modifier la configuration en augmentant le nombre de caractères en-dessous duquel l’OCR se déclenche automatiquement. Attention toutefois à bien vérifier les résultats car l’OCR supporte mal les multiples langues. Pour ce faire, rendez-vous dans l’onglet “Configuration”.
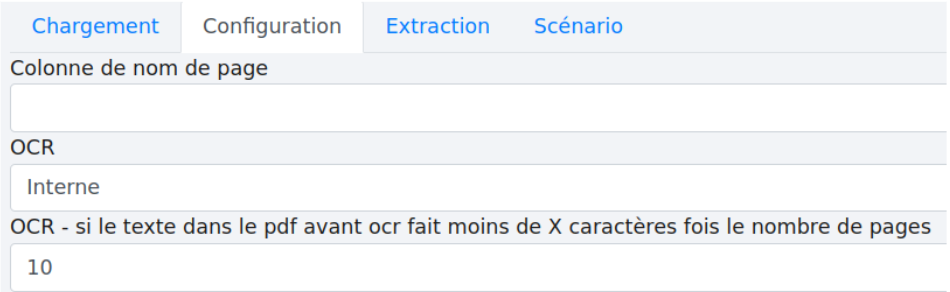
Augmentez le nombre de caractères pour être sûr de déclencher l’OCR (ex : 100000).
Puis retournez dans l’onglet “Chargement”, retirez le document, rechargez-le et analysez-le de nouveau.
# 2 - Créer les règles d’extraction
Rendez-vous dans l’onglet “Extraction”. Le document apparaît dans la fenêtre à la première page par défaut. Vous pouvez changer de page ici :  .
.
# 2.1 - Navigation
Positionnez la souris sur la fenêtre de visionnage du document. La molette de la souris gère le zoom. Maintenez enfoncé le bouton gauche de la souris pour déplacer le document.
Si vous ne savez plus où vous êtes dans le document, cliquer sur le bouton  repositionne le document dans sa position initiale.
repositionne le document dans sa position initiale.
# 2.2 - Texte extractible
La transformation du pdf en texte extractible se matérialise par des textes soulignés de bleu. Dans le cas contraire, le texte du pdf n’est pas extractible car c’est en fait une image.
Texte extractible :  .
.
Image :  .
.
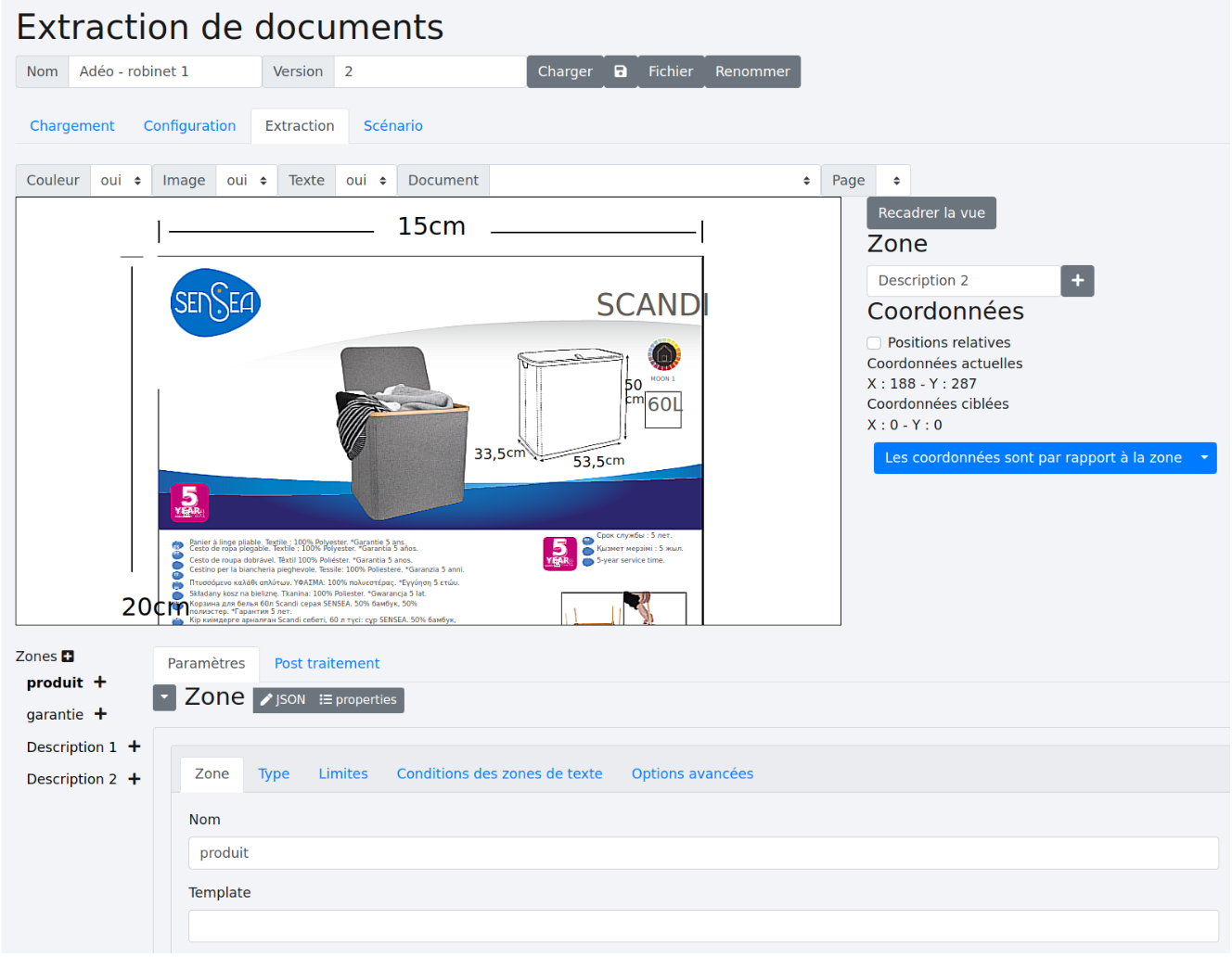
Si le texte est extractible, vous pouvez commencer la création du scénario. Par défaut, une première zone est créée et nommée “zone 0”.
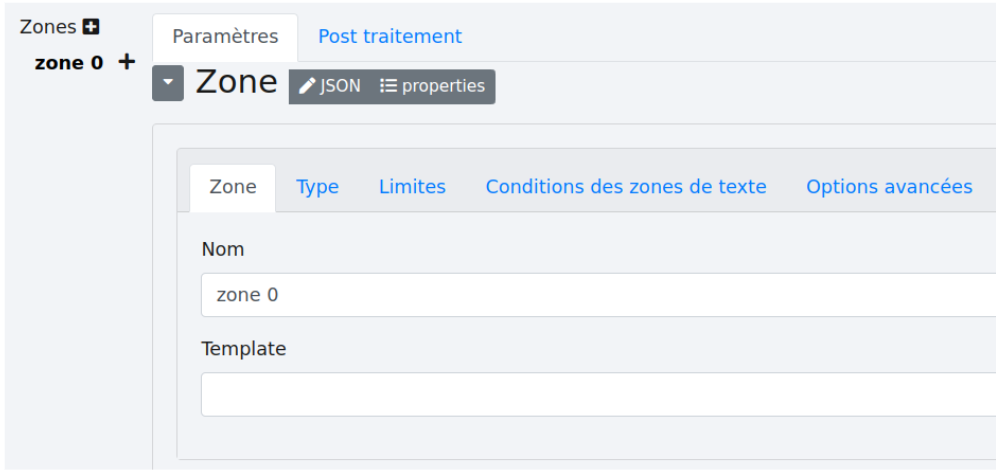
Renommez la.
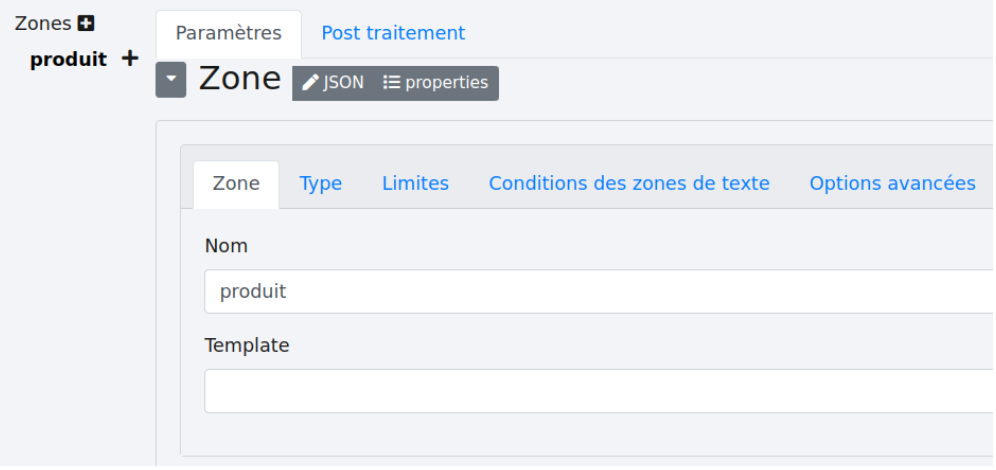
Puis sélectionnez la zone du document où vous récupérez le nom du produit en maintenant le bouton droit de la souris enfoncé et en déplaçant la souris. Cliquez sur le bouton “Test”. La zone apparaîtra en violet et le résultat de l’extraction apparaîtra sous le bouton “Test”.
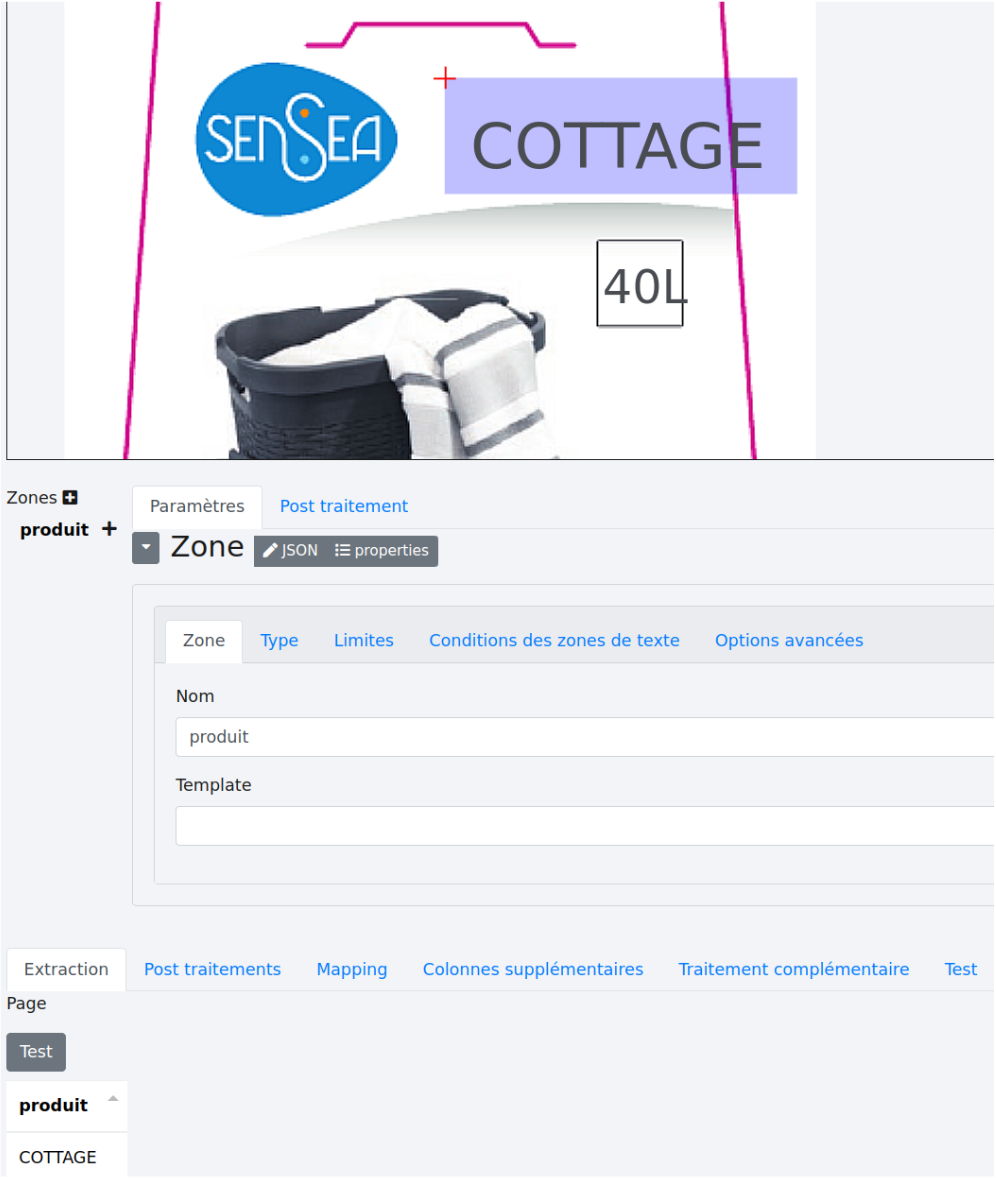
# 2.3 - Ajout d’une zone
Il suffit de cliquer sur le petit bouton “+” à côté de “Zones”  . La nouvelle zone apparaît.
. La nouvelle zone apparaît.
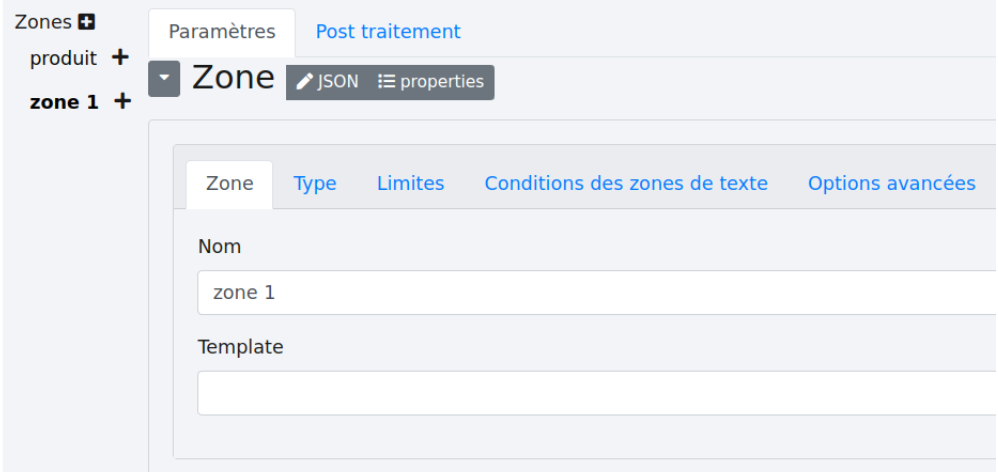
Répétez la définition des zones jusqu’à épuisement des données souhaitées.
# 2.3.1 - Découper une zone de texte
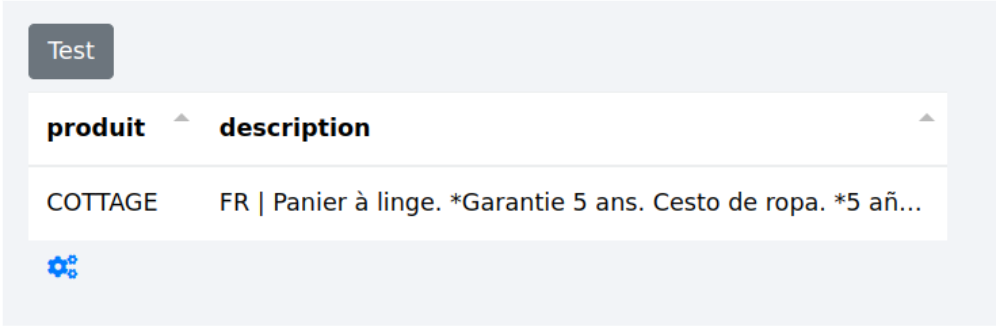
Il peut arriver qu’on veuille découper une zone de texte en plusieurs lignes pour créer plusieurs zones de récupération par exemple.

Ici, les 5 langues sont récupérées dans une seule zone de texte correspondant à la première ligne (FR). Les 5 descriptions apparaissent alors après le FR lors de l’extraction.
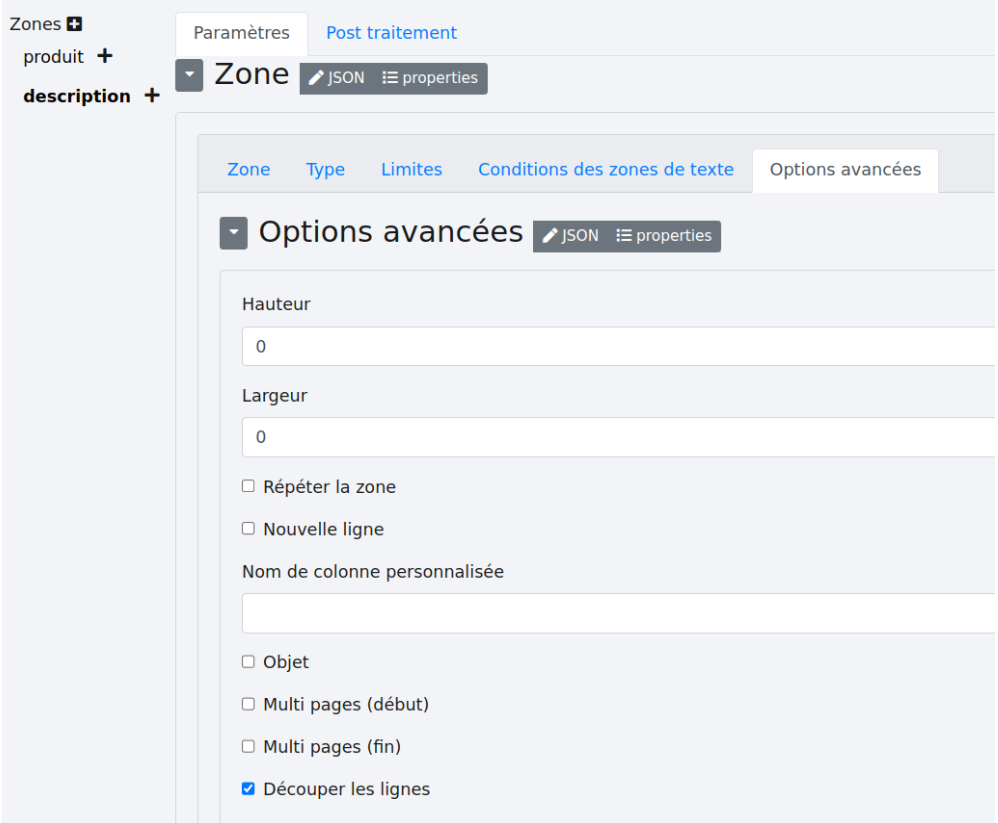
Afin d’éviter cela, allez dans l’onglet “Options avancées” et cochez la case “Découper les lignes”.
L’extraction sera alors la suivante :
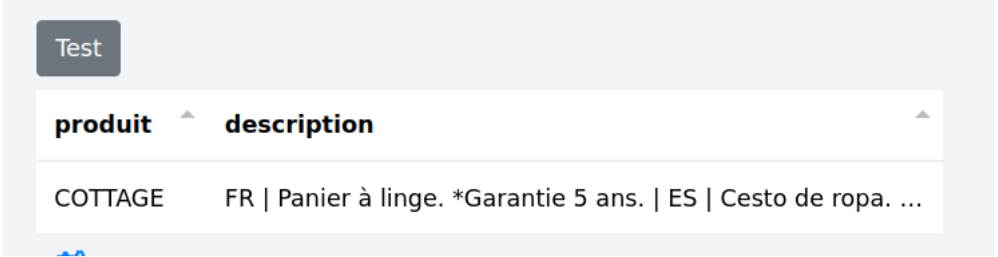
Chaque langue est alors suivie de sa description.
# 2.3.2 - Les post traitements
Certaines extractions nécessitent un post traitement afin de bien répartir les informations dans les bonnes colonnes ou de nettoyer la colonne.
Après avoir testé l’extraction de la zone voulue, cliquez sur l’onglet “Post traitement”. Les données extraites de la zone sont reprises.
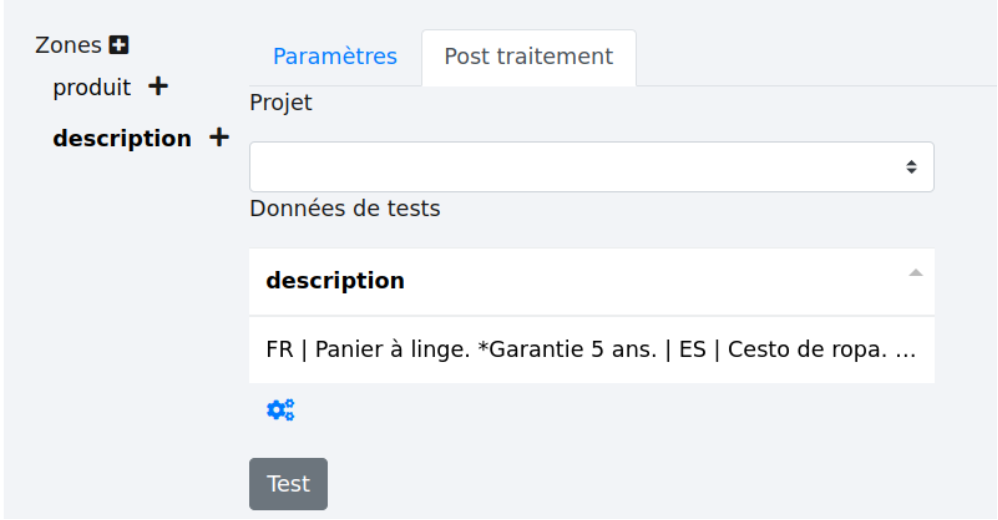
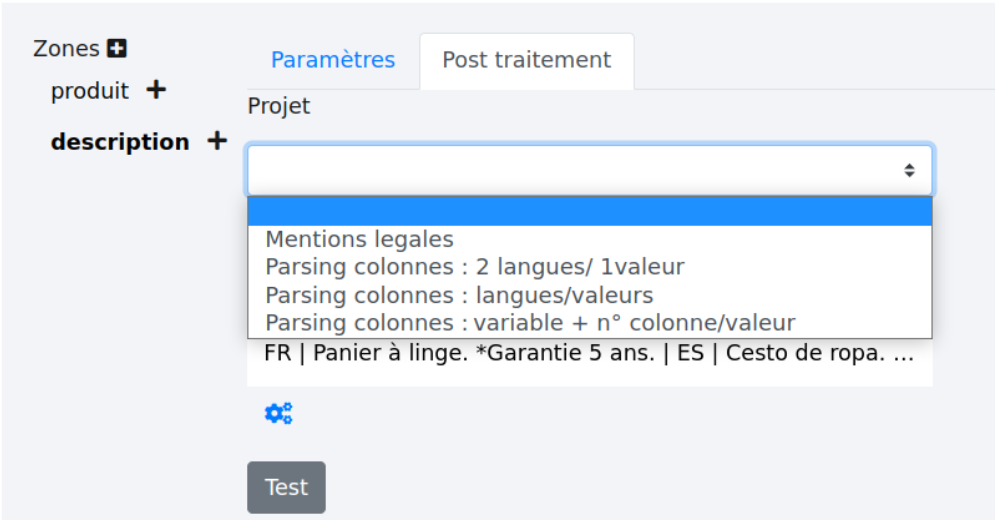
Selon les données extraites, plusieurs post traitements sont accessibles. Ici, l’ordre des informations est toujours : la première langue suivie d’un “|” puis de sa description, puis la seconde langue, un “|” et sa description, etc. Cela correspond au post traitement “Parsing colonnes : langues/valeurs”. Il faut alors sélectionner ce post traitement dans la liste déroulante.
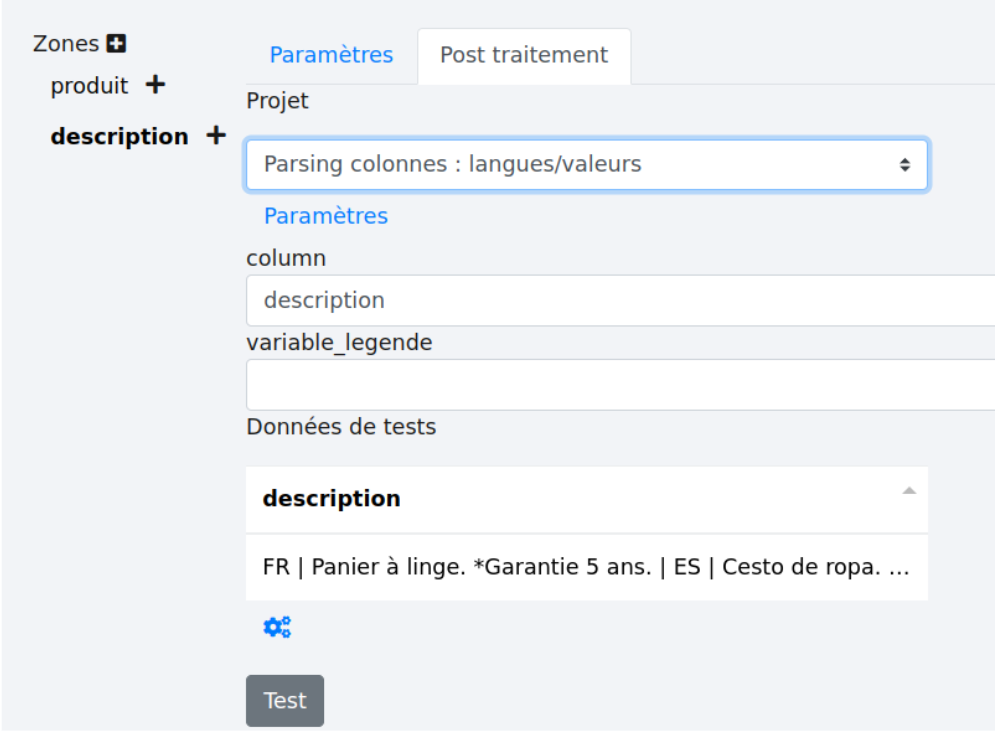
Il reste à nommer la variable de légende puis à cliquer sur “Test” pour voir le résultat. Exemple :
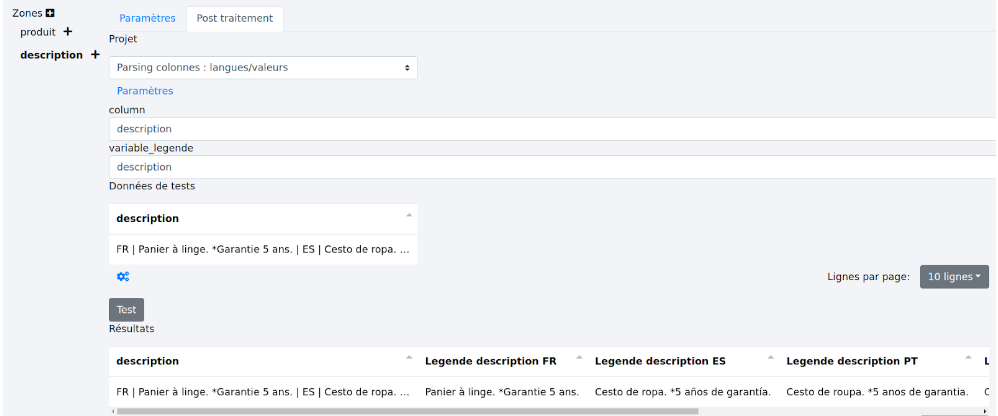
Le contenu de la colonne de travail “description” a servi de base pour la création des colonnes suivantes. Pour chaque langue, nous avons une colonne de description portant l’intitulé “Légende description langue” et comme contenu le texte descriptif.
# 2.3.3 - Liste des post traitements
Parsing colonnes : 2 langues/1 valeur Utilisé dans le cas où nous avons deux langues pour une seul description comme ici :

Les données sont récupérées ainsi :
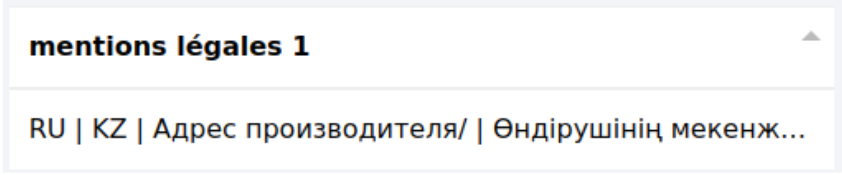
et sont dispatchées comme cela :
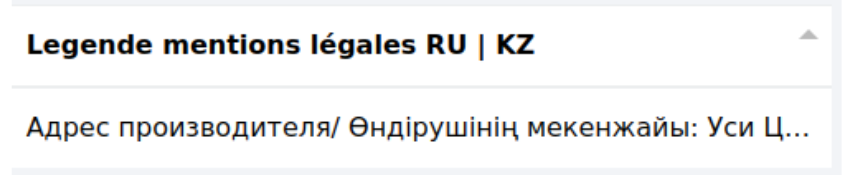
Parsing colonnes : langues/valeurs Un cas fréquent se présentant ainsi :

Récupération des données :
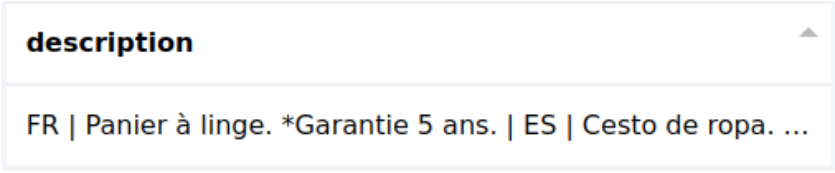
Dispatch des données :

Parsing colonnes : variable + n° colonne/valeur
Récupération des données :
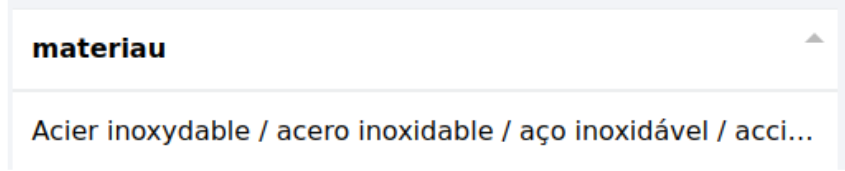
Dispatch :

Pour couvrir vos besoins, d’autres post traitements pourront être créés à la demande. N’hésitez pas à nous contacter.
# 2.4 - Documents multi-pages
Dans le cas où les informations recherchées sont réparties sur plusieurs pages, définissez les zones voulues page par page et précisez la page sur laquelle doit agir chaque zone (dans le cas contraire, la zone cherchera des informations sur chaque page). Pour ce faire, rendez-vous dans l’onglet “Options avancées”, champ “Page”.


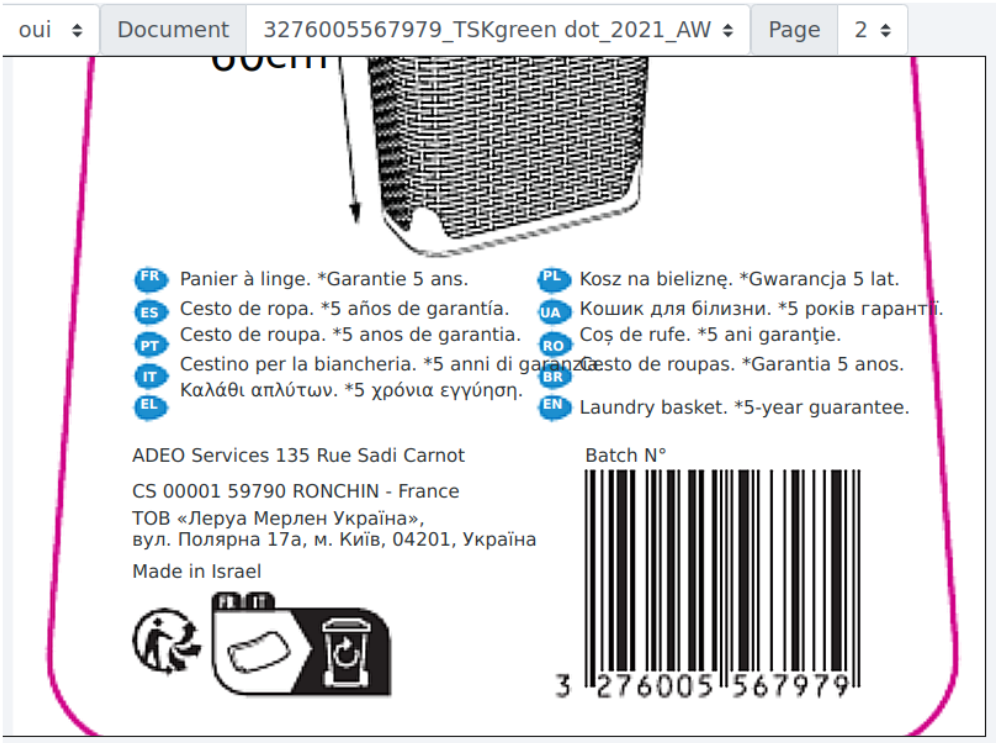
Exemple : On doit récupérer le nom du produit et la garantie sur la première page. Les descriptions sont en seconde page.
Page 1 :

Page 2 :
Les trois zones sont listées ainsi dans le scénario :

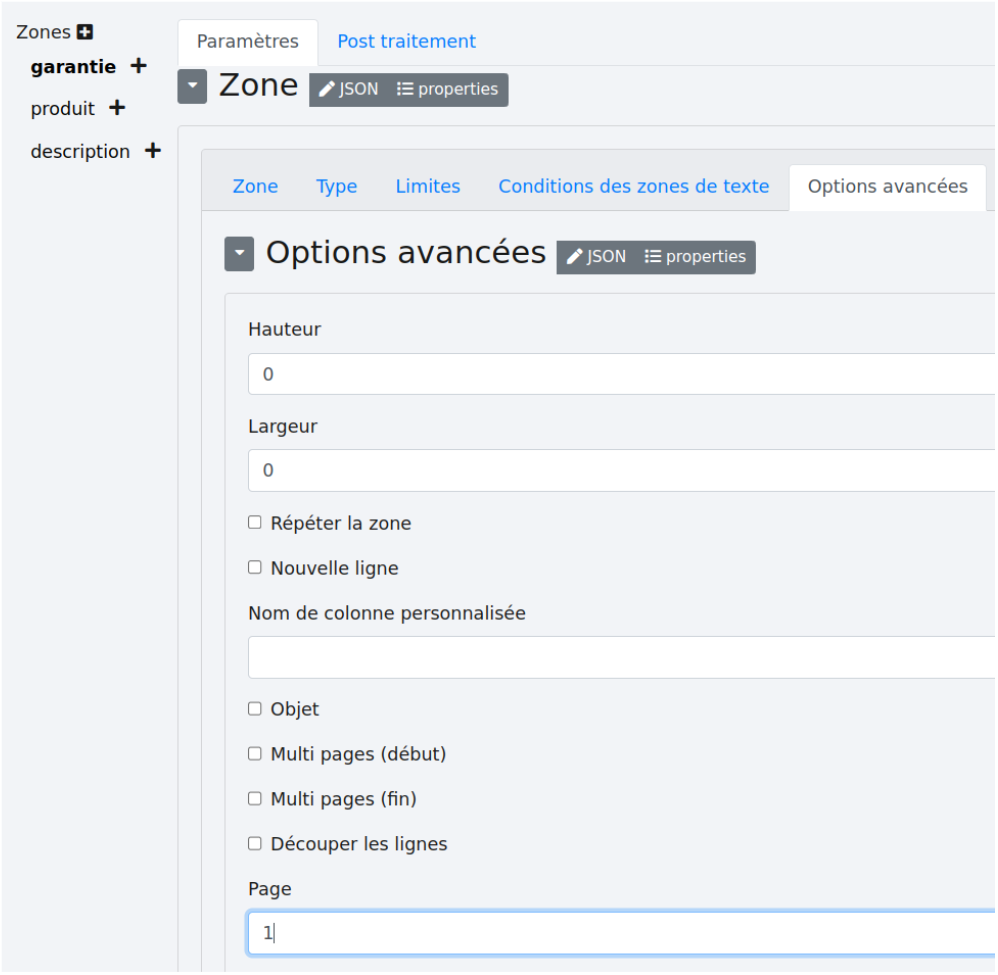
Les options avancées des zones “garantie” et “produit” sont comme ceci :
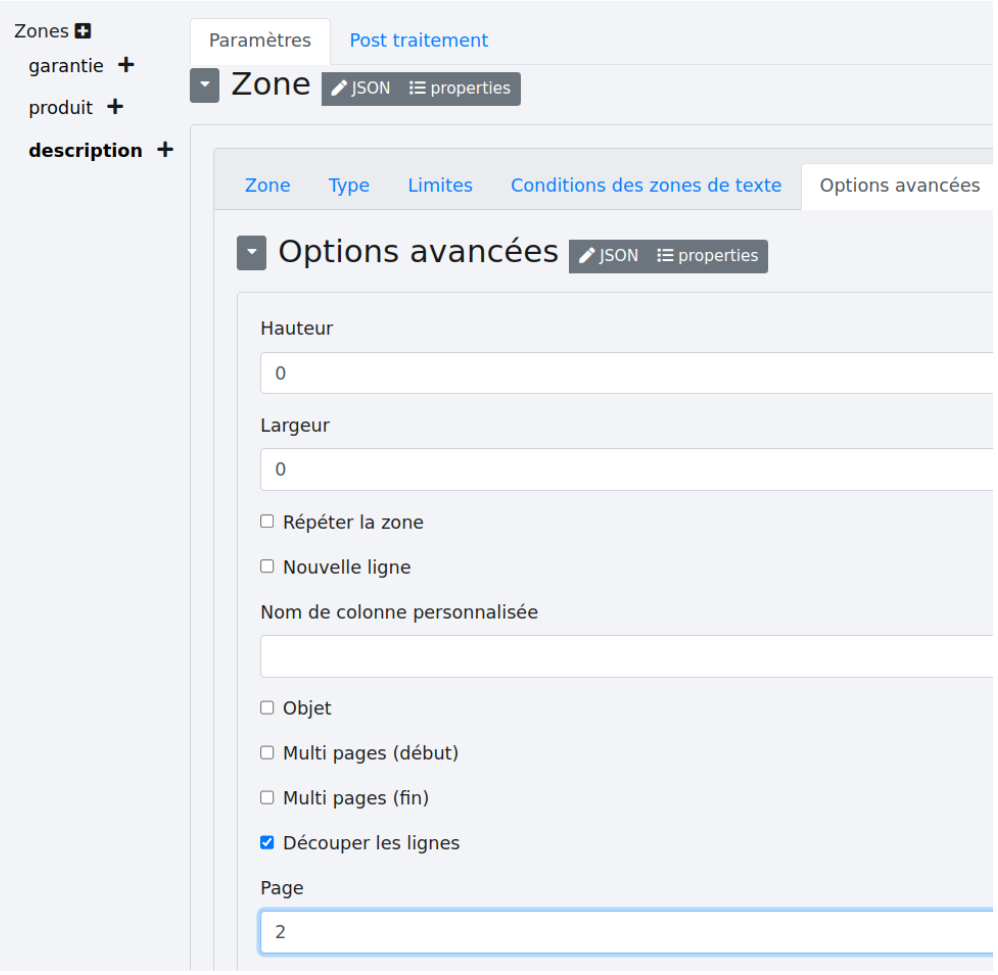
Quant à la zone “Description”, voici ses options :
Tester l’extraction sur l’ensemble des pages du fichier nécessite de tester le fichier avec le bouton
 . On obtient alors un tableau avec une ligne par page.
. On obtient alors un tableau avec une ligne par page.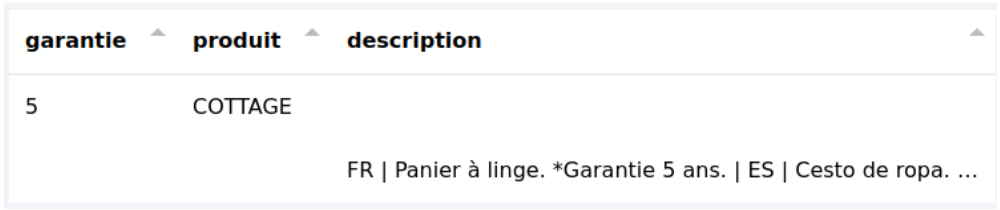
La première ligne correspond à l’extraction de la première page, la seconde à la page 2. Toutes les lignes seront regroupées sur une seule avec un traitement complémentaire spécifique.
# 3 - Actions sur l’ensemble du fichier
Les onglets de bas de page présentent différentes actions hors définition des extractions.
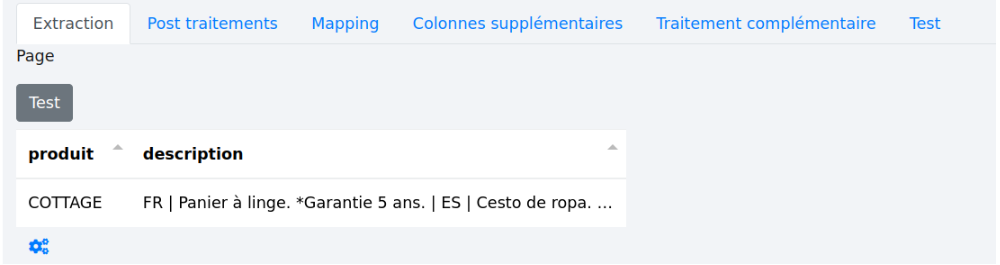
# 3.1 - Extraction
Permet de tester l’extraction des zones (mais pas de les définir). C’est l’onglet par défaut.
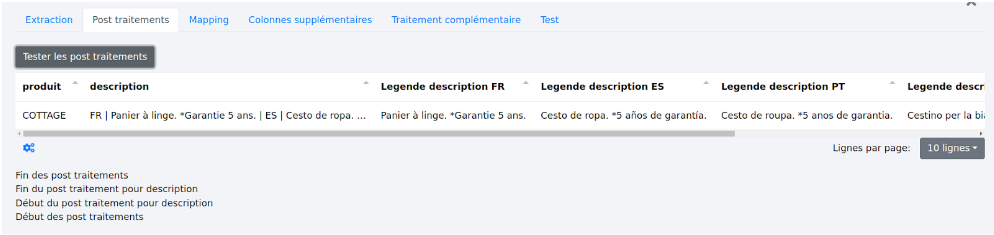
# 3.2 - Post traitements
Il s’agit là de lancer tous les post traitements définis dans toutes les zones sur l’ensemble du fichier.
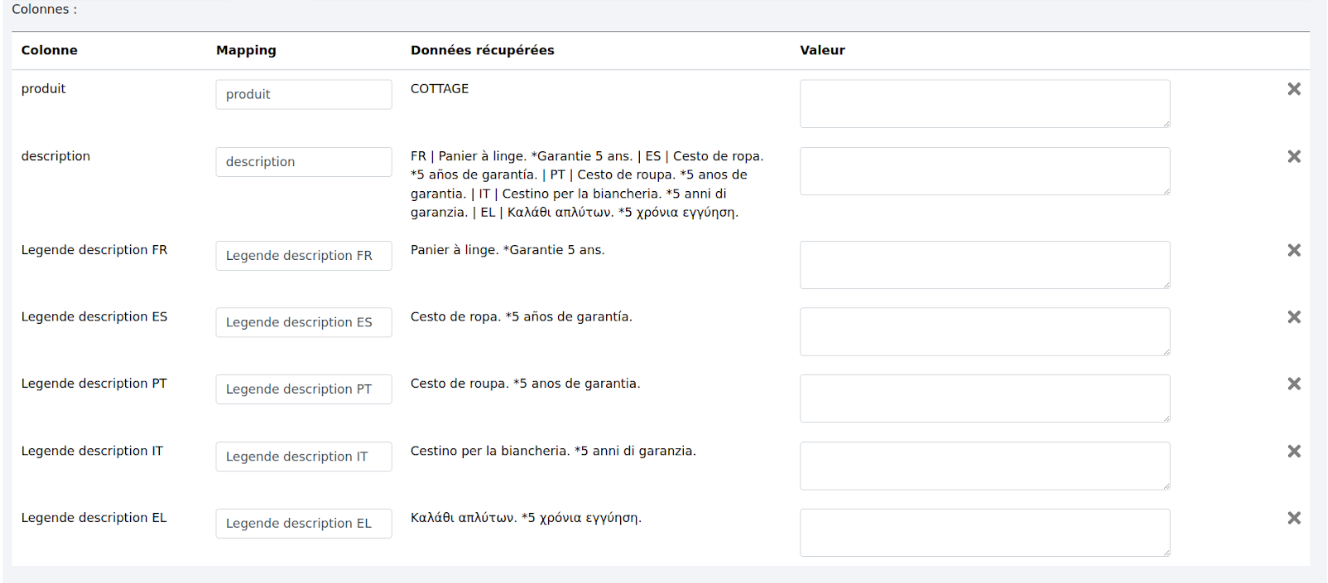
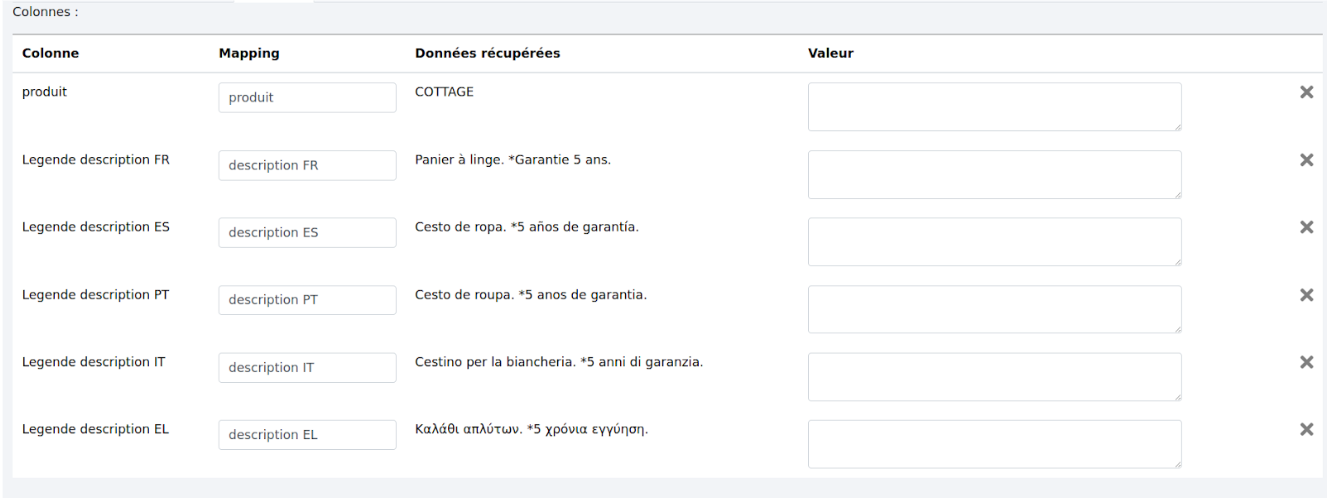
# 3.3 - Mapping
Permet de renommer les colonnes et d’éliminer les colonnes qu’on ne veut pas conserver dans le fichier de sortie. Par exemple ici, nous allons retirer la colonne “description” (en cliquant sur la croix à droite de la ligne  ) qui est une colonne de travail et renommer les colonnes de descriptions par langues.
) qui est une colonne de travail et renommer les colonnes de descriptions par langues.
# 3.4 - Colonnes supplémentaires
C’est ici que se définissent les picto présents dans le document.
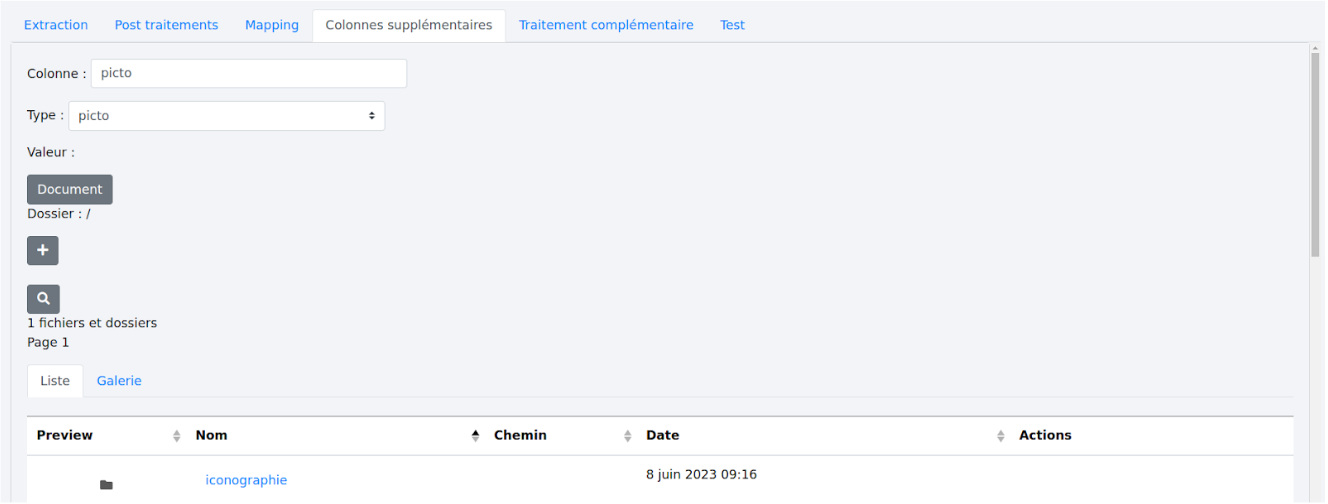
La colonne est nommée “picto” par défaut. il reste possible de la renommer.
Cette fenêtre offre une vue sur l’espace document où sont stockés les picto. Cliquez sur le dossier “iconographie” pour l’ouvrir. Le contenu apparaît sous forme de liste par défaut mais il est possible de les voir en mode “galerie”. Les fichiers et dossiers sont triés par ordre alphabétique.
Cliquez sur  pour remonter dans l’arborescence des dossiers.
pour remonter dans l’arborescence des dossiers.
Chaque page affiche 20 fichiers et/ou dossiers. Les flèches bleues permettent de naviguer entre elles.
Vous pouvez organiser les picto comme bon vous semble. Soit ils sont tous dans le même dossier et vous effectuerez des recherches par noms (par exemple) pour les filtrer, soit vous les organisez en sous dossiers (par grandes catégories par exemple).
# 3.4.1 - Ajouter un dossier ou des fichiers
Cliquez sur le bouton  ouvre une section où vous pouvez ajouter un dossier ou des fichiers.
ouvre une section où vous pouvez ajouter un dossier ou des fichiers.
L’ajout d’un dossier se fait simplement en écrivant le nom du nouveau dossier dans le champ sous “Ajouter un dossier”
par exemple ici “poubelles” :
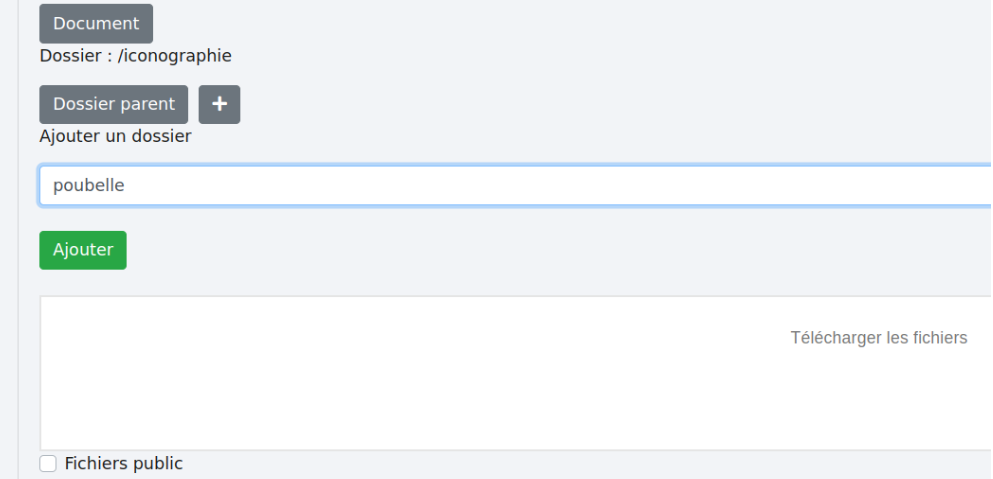
puis en cliquant sur “Ajouter”.
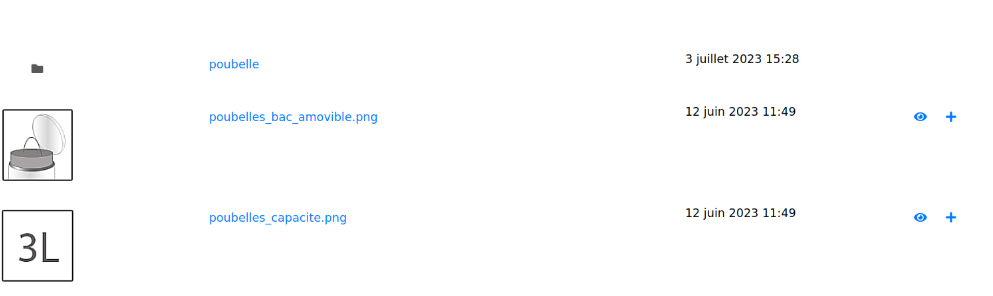
L’ajout de fichiers est similaire. Cliquez sur le bouton puis glisser/déposer les fichiers dans l’espace dédié ou cliquez sur “Télécharger les fichiers”. Le bouton “Ajouter” les ajoutera dans le dossier où vous vous trouvez.
Exemple : j’entre dans le dossier “poubelle” pour y ajouter deux fichiers. On peut voir l’adresse ici :
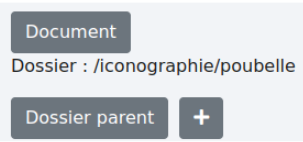
Puis je clique sur le bouton “Valider” sous les deux fichiers. Et ils apparaissent dans le dossier “poubelle” récemment créé qui ne comporte bien que deux fichiers.
# 3.4.2 - Ajouter des picto
Cette fonctionnalité permet d’ajouter des picto lorsqu’ils sont présents dans le document. Pour ce faire, naviguez dans le dossier où se trouve les picto puis faites une recherche en cliquant sur la loupe. Une section de recherche apparaît.

Vous pouvez chercher les picto par nom, date ou tag. Dans le cas de la panière à linge, nous recherchons le mot “panier”.

Un seul picto est présent.

Je l’ajoute dans la colonne “picto” en cliquant sur le  . Le picto apparaît dans la sélection en dessous et le “+” devient “-”.
. Le picto apparaît dans la sélection en dessous et le “+” devient “-”.
Vous pouvez retirer le picto de la sélection en cliquant sur le  directement dans la description du picto ou sur la
directement dans la description du picto ou sur la  sur la ligne du picto dans la sélection.
sur la ligne du picto dans la sélection.

ou
Pour une recherche avec un plus grand nombre de picto, cela peut donner ceci :
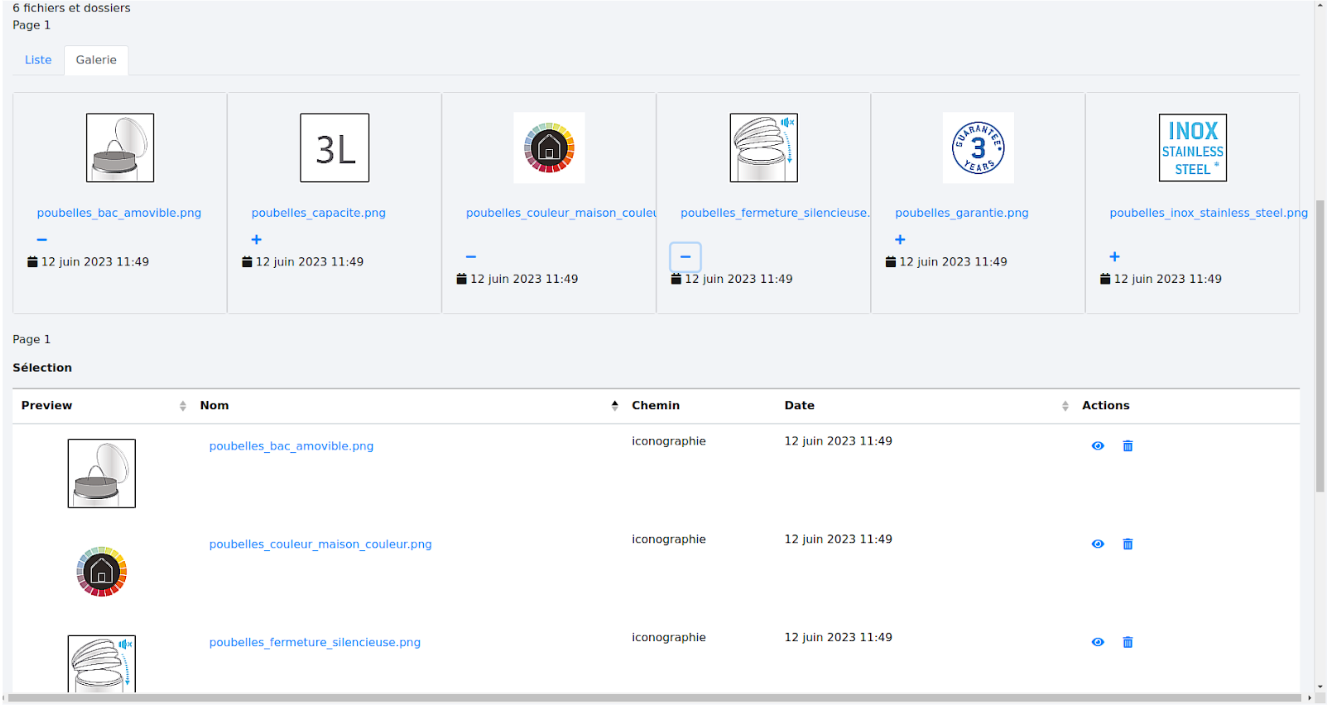
Nous retrouvons la liste des picto présents dans la colonne en haut de la fenêtre :

# 3.4.3 - Ajouter une colonne avec une valeur fixe
Vous pouvez ajouter une colonne avec une valeur fixe dans le cas d’une valeur vectorisée non reconnue par exemple. L’ajout se fait alors dans cet onglet. Voyons comment avec un exemple.
Ici, les dimensions ne sont pas récupérées alors que vous en auriez besoin.
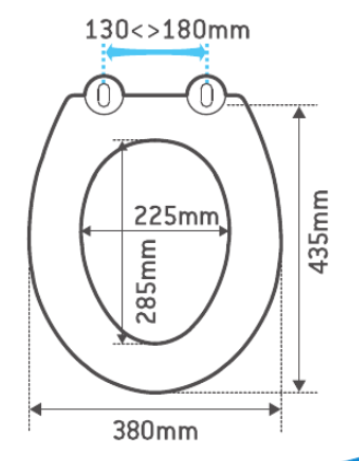
Rendez-vous dans l’onglet “Colonnes supplémentaires”.

Ici, vous avez déjà une colonne “picto” regroupant les pictogrammes du document. Faites défiler la section vers la bas jusqu’à voir apparaître le en bas à gauche.
Cliquez sur le pour créer une nouvelle colonne.

Laissez l’option du menu déroulant à vide.

Cliquez sur  . Une nouvelle colonne apparaît.
. Une nouvelle colonne apparaît.

Nommez-la, laissez le type à vide et donnez lui sa valeur.

Vous pouvez vérifier la présence de la colonne et de sa valeur en retournant dans l’onglet “Extraction” et tester.

Enregistrez pour conserver les modifications. Attention! Cette colonne à valeur fixe se retrouvera dans tous les fichiers traités. Cette méthode ne peut être utilisée que sur des produits ayant cette caractéristique et cette valeur.
# 3.5 - Traitements complémentaires
Permet d’ajouter un traitement qui travaillera sur le fichier global. Par exemple, le traitement “Adéo” permet d’obtenir une seule ligne par fichier et crée une colonne par picto.
# 3.6 - Test
Permet de tester l’intégralité des onglets précédemment vus, de l’extraction aux traitements complémentaires avant de valider le scénario.
Nous y retrouvons bien la colonne “picto” et chaque colonne de picto par exemple.

# Lancer un traitement
Une fois que le scénario est configuré et enregistré, il est possible de traiter un ou plusieurs fichiers. Sélectionnez “Traitement” dans le menu de gauche.
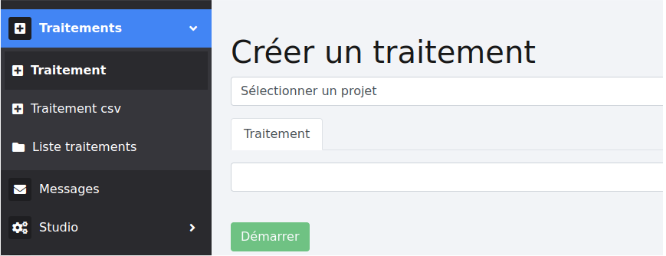
Sélectionnez le scénario voulu dans la liste déroulante “Sélectionner un projet” puis chargez un ou plusieurs fichiers correspondant au format utilisé dans le scénario.
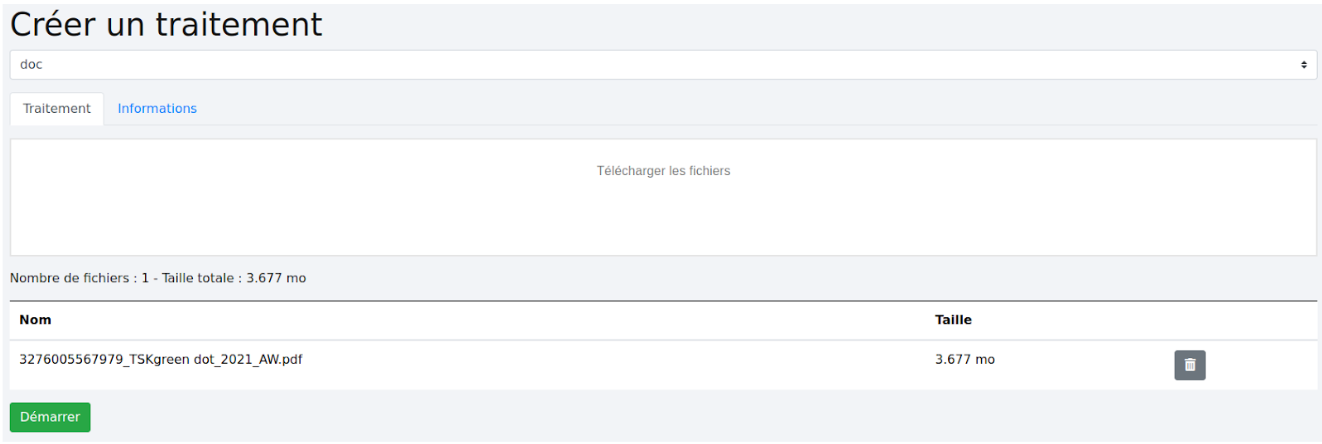
Cliquez sur “Démarrer” pour lancer le traitement.
Le résultat est un fichier téléchargeable.