# Création d’un scénario
- Ajouter une étape
- Lancer une étape
- Les étapes
- API
- Base de données
- Chercher et classer
- Conversion
- Correspondance
- Deux points
- Envoi de mail
- Fonction sur colonne
- Fonctions Excel (en cours d’écriture)
- Conditions
- Présentation d’une fonction type
- Fonctionnalités génériques
- ARRONDI
- ARRONDI.INF
- ARRONDI.SUP
- ASSIGNER
- COMMENCE PAR
- CONCATENER
- CONTIENT
- CONVERSION DIACRITIQUES
- EQUIV
- EXTRAIRE
- EXTRAIRE INTERVALLE
- FINIT PAR
- ISOLER
- MAJUSCULE
- MINUSCULE
- NBCAR
- N0.SEMAINE
- NOMBRE ENTIER
- NOM PROPRE
- NOM PROPRE2
- PARSER
- PUISSANCE
- SPLIT
- SUBSTITUE
- TRIM
- Fusionner lignes
- Générer document
- Hit Parade
- INSEE
- Mapping colonnes
- Mapping colonnes - fichier cible
- Mode regex
- Normalisation
- Partage de document
- Projet
- Référentiel
- Script personnalisé
- Siren
- Sort
- Split
- Split JSON
- Supprimer lignes
- Textrazor
- xlsx
- Zip
- Les regex
# Ajouter une étape
 ajoute une nouvelle étape en fin de scénario par défaut. Il est ensuite possible de la glisser/déposer à l’endroit voulu.
ajoute une nouvelle étape en fin de scénario par défaut. Il est ensuite possible de la glisser/déposer à l’endroit voulu.
D’une manière générale, toutes les opérations ont des descriptions éditables. Il est conseillé de décrire les opérations pour les retrouver plus rapidement.
Un certain nombre d’étapes offrent la possibilité d’ajouter des conditions sur les lignes.
Cliquer sur  fait apparaître un query builder :
fait apparaître un query builder :
 Dès lors, les actions de l’étape n’agiront que sur les lignes concernées par ces conditions.
Dès lors, les actions de l’étape n’agiront que sur les lignes concernées par ces conditions.
 fait apparaître le fichier json de l’étape qu’il est possible d’éditer ou de copier/coller dans une nouvelle étape.
fait apparaître le fichier json de l’étape qu’il est possible d’éditer ou de copier/coller dans une nouvelle étape.
# Lancer une étape
Chaque étape dispose de ces deux boutons :

Les données entrantes d’une étape sont soit les données initiales s’il s’agit de la première étape du scénario, soit les données de la précédente étape.
Le bouton "test" permet de tester rapidement le résultat de l’étape courante.
Le bouton "test depuis la première étape" relance le scénario complet. C’est utile notamment lorsque les données initiales ont changé (nouveau fichier test) ou lorsqu’une étape précédente a été modifiée.
# Les étapes
Voici la description des différentes étapes pouvant constituer un scénario classées par ordre alphabétique.
# API
Cette étape permet d’effectuer des requêtes API. Les paramètres par défaut précisent les colonnes de résultats et d’erreurs, l’action à entreprendre (GET, POST, etc) et le temps d’attente entre deux requêtes (dépendant de l’API).
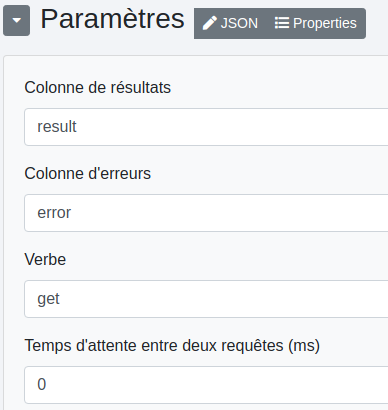
Par défaut, l’étape va chercher l’adresse de l’api dans une colonne "uri" (et non "url") dans le csv, et ce pour chaque ligne.
Dans le cas où le csv ne contient pas cette colonne, on doit ajouter l’adresse de l’api en cliquant sur "Properties" puis en cochant "url".
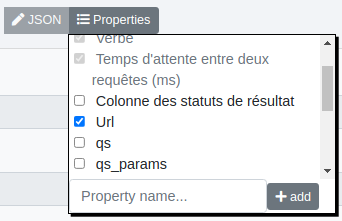
Un nouveau champ apparaît où il est possible d’ajouter l’adresse de l’API.

Exemple de sortie :

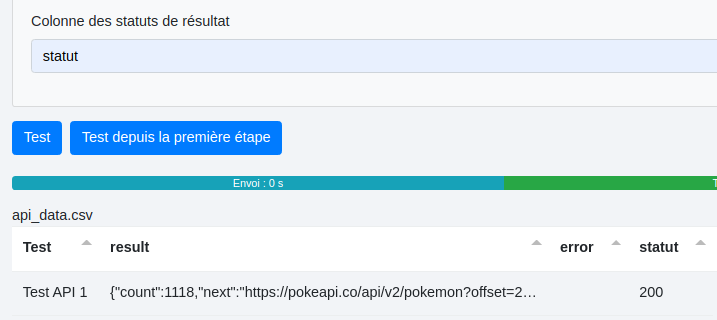
Cocher la "Colonne statuts de résultats" nous donne les codes d’état de la réponse HTTP (200,400, etc).
D’autres éléments de requête sont possibles :
- qs : "Query string" et ses paramètres tels que "offset", "limit" et "page". Il s’agit de la partie après le "?" comme ici :

- header : contenant notamment les paramètres d’authentification;
- body : contenant le corps de la requête;
- form : utile pour l’action POST par exemple;
- formdata : utile notamment pour le transfert de fichiers.
Tous peuvent être entrés de deux manières :
- Soit ils ont leurs propres colonnes dans le csv d’entrée, auquel cas les cases "qs", "header", "body", "form" ou "formdata" doivent être cochées dans le menu "Properties";
- Soit le csv ne les contient pas et il faut les ajouter en cochant les cases "qs_params", "header_params", "body_params", "form_params" ou "form_data_params".
Voyons un exemple avec qs et qs_params.
- Avec "qs" :
Nous avons ce fichier csv en entrée où les paramètres "limit" et "offset" sont précisés :

Nous cochons la case "qs" dans le menu "Properties" :
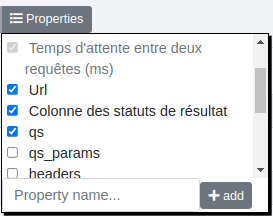
Puis précisons les colonnes dans les nouveaux champs :

Ce qui nous donne la sortie suivante :

avec ce json :
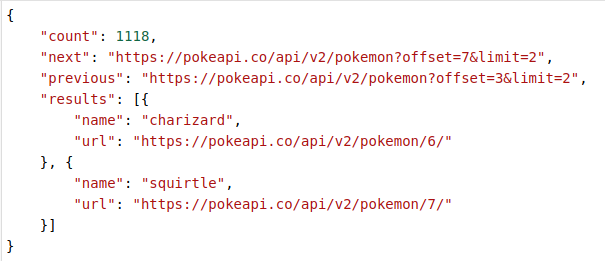
- Avec "qs_params" maintenant :
Cette fois, nous n’avons aucun paramètre dans le csv d’entrée.

Nous cochons la case "qs_params" des "Properties".
Puis ajoutons les paramètres souhaités ici :

"Offset" et "limit" sont des nombres. Nous devons modifier leurs types grâce aux menus déroulants les jouxtant puis entrer leurs valeurs.
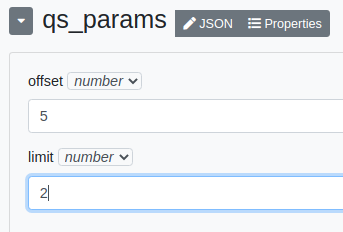
Le résultat est identique à l’exemple précédent avec "qs".
# Base de données
Cette étape permet de réaliser de nombreuses opérations sur ou à partir d’une base de données. Il faut commencer par choisir le type d’action voulue dans le menu "Paramètres".
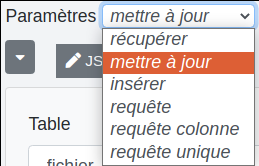
# Récupérer
Ce choix permet de récupérer des données issues de la base.
Le menu déroulant "Table" permet de sélectionner la table cible.

Personnaliser select : permet de limiter la récupération à quelques colonnes seulement par exemple.

Personnaliser la fin de requête : permet de préciser la limite du nombre de résultats ou encore de les classer avec un "order by".

Unique : doit être cochée pour aller chercher les données dans la BDD et non dans les données initiales.

Si elle n’est pas cochée, la requête s’effectue pour chaque ligne du csv. Deux colonnes "response" et "error" leur sont ajoutées. "Response" contient le résultat de la requête sous format json. C’est notamment utile pour des requêtes dynamiques prenant les différentes valeurs d’une même colonne du csv en entrée (voir l’exemple de l’étape requête).
Recherche : permet de préciser la recherche à effectuer sur une ou plusieurs colonnes. Cette section doit comporter au moins une recherche.

Les types de recherche peuvent être par valeur ou par colonne. Dans ce cas, les valeurs de la colonne spécifiée sont recherchées dans la colonne cible. Les comparaisons offrent diverses options :
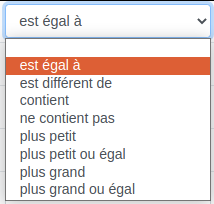
Colonne de résultats : permet de renommer la colonne de résultats. Fonctionne pour la récupération, la mise à jour et l’insertion. Pratique lors de plusieurs appels consécutifs en base de données afin de ne pas écraser les résultats de l’appel précédent. Par exemple ici, nous faisons deux appels consécutifs. Le premier concerne la table "formation" et le second, la table "contact".

# Mettre à jour
On peut ici mettre à jour la base de données. L’étape se décompose en trois parties.
Table :
Il s’agit ici de choisir la table cible.
Mapping :
Il s’agit là de déterminer quels contenus sont à ajouter et dans quelles colonnes de la table.
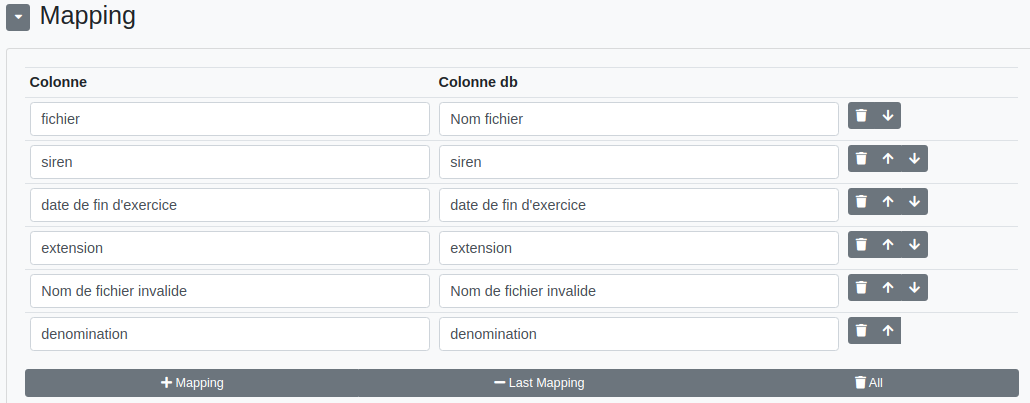
Colonnes uniques :
Les colonnes uniques précisent les enregistrements de la table qui devront être modifiés.

# Insérer
Insert un nouvel enregistrement dans la table cible.
Table : on sélectionne la table cible.
Mapping : on fait correspondre les colonnes du fichier entrant avec les colonnes de la table pour les contenus à insérer.
Colonnes uniques : Obligatoire. Il s’agit là d’une sécurité. Si l’enregistrement existe déjà, l’étape renvoie une erreur.

# Requête
Nous avons un fichier csv en entrée.
Permet d’écrire manuellement une requête SQL dynamique qui sera exécutée pour chaque ligne du fichier csv. La réponse se trouvera dans la colonne "response" sous format json.

Nous avons par exemple cette table en BDD :
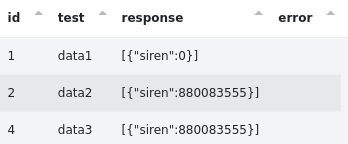
Et nous effectuons cette requête qui récupère le champ "siren" pour les id présents dans le csv :
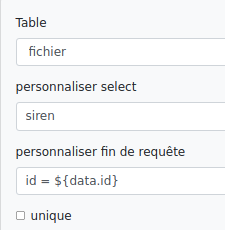
La notation ${data.nomColonne} permet d’adapter la requête en fonction des données de la colonne pour chaque ligne du csv.
Ce qui nous donne :
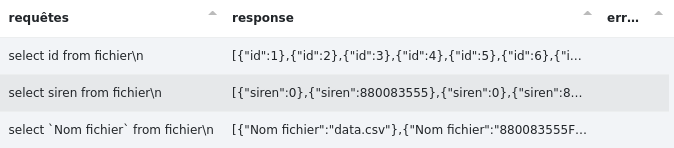
# Requête colonne
Permet d’exécuter une liste de requêtes stockées dans une colonne du csv d’entrée. La réponse se trouvera dans la colonne "response" sous format json.

Données initiales :

Résultat :
# Requête unique
Contrairement à l’habitude, les données d’entrée de cette étape ne peuvent être que les données d’une table et non pas un csv.
Par exemple, cette requête renvoie les champs "id" et "publication" des 5 premiers enregistrements de la table "bodacc".

Résultat :
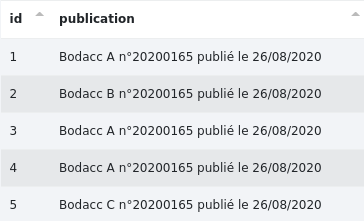
Le résultat est ici un csv complet directement utilisable (absence de colonne "response" et de fichiers json).
# Chercher et classer
Comme son nom l’indique, sa fonction est de chercher et classer des données.
Par défaut, les caractères non alphanumériques sont exclus des mots mais il est possible d’en inclure en le déclarant dans ce champ :

Ici, le tiret "-" sera inclus dans les mots.
Les recherches se composent de quatre champs :
- Colonne de recherche : la colonne où l’information est recherchée.
- Colonne de destination : la colonne où l’information trouvée sera stockée. Elle peut être vide.
- Valeur de recherche : peut être un mot, un nombre, une chaîne de caractères, un regex, le nom d’une liste ou d’une colonne selon le type de recherche à effectuer.
- Type de recherche : (choix obligatoire) il y a trois types possibles :
Valeur : on recherche une valeur dans la colonne de recherche. Cela peut être un mot, un nombre, une chaîne de caractères ou un regex par exemple.

Dans cet exemple, on recherche le degré d’alcool grâce à un regex dans la colonne “Libellé Brut” et on le met dans le nouvelle colonne “degré alcool”. La seconde ligne élimine le degré d’alcool de la colonne “Libellé travail”.
Avant :
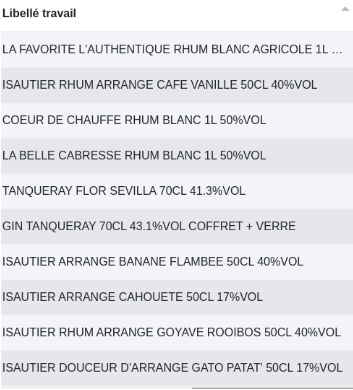
Après :
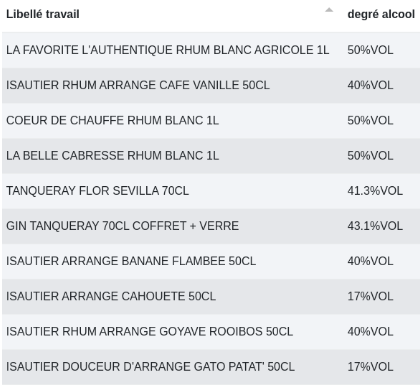
Colonne : le nom d’une colonne est entré dans la valeur de recherche. Pour chaque ligne, on recherche l’information de cette colonne dans la colonne de recherche.

Ici, on recherche les marques dans la colonne “Libellé travail”. En l’absence de colonne de destination, l’information trouvée ne sera pas stockée. En revanche, parce que la valeur de remplacement est vide, l’information sera effacée du “Libellé travail. Cela permet de rapidement et simplement nettoyer la colonne cible.
Avant :

Après :

Liste : le nom d’une liste est entré dans la valeur de recherche. Pour chaque ligne de la colonne de recherche, on recherche si elle contient une donnée contenue dans la liste.

Ici, nous cherchons les pays faisant partie de la liste “pays” dans la colonne “Origines”. Les pays trouvés passent en majuscules.

Autre cas :
![]()
Nous cherchons les valeurs de la liste “familles” dans la colonne “Famille” pour les mettre dans la colonne “LOGO” puis remplacer les valeurs correspondantes de cette dernière colonne par “SURGELÉ”.
La liste “familles” contenant les valeurs à rechercher :
![]()
![]()
Valeur de remplacement : valeur par laquelle l’information recherchée sera remplacée. Peut être vide. Il peut s’agir d’un mot, d’un chiffre, d’une chaîne de caractères ou d’une fonction JavaScript permettant d’effectuer une opération sur la valeur trouvée.

Ici, les pays sont mis en majuscules.
Dans l’exemple ci-dessous, toutes les variantes des États-Unis seront trouvées et remplacées par "États-Unis" grâce au code JavaScript "${list[match]}".


Avant :
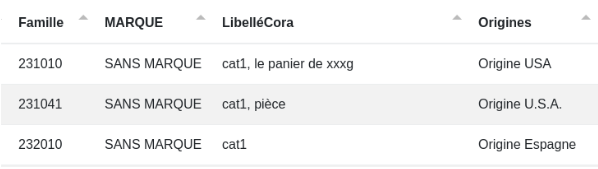
Après :
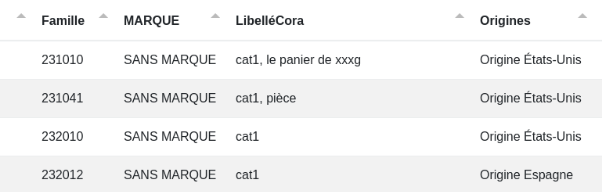
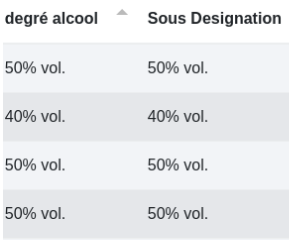
Enfin, il est possible de copier le contenu d’une colonne dans une autre de cette façon :

Cette action permet de placer les données de la colonne “degré d’alcool” dans une nouvelle colonne “Sous Désignation”. La colonne “degré d’alcool” existe toujours.
# Conversion
Cette étape permet de convertir des unités : monnétaires,poids et autres mesures, etc.
Il faut tout d’abord créer une liste de conversion comme ici la conversion dollar-euro :
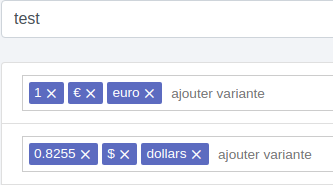
Chaque ligne comporte un nombre suivi de ses unités, variantes comprises le cas échéant.
En partant de ces données initiales :

Voici le paramétrage à effectuer pour convertir le prix en dollars.

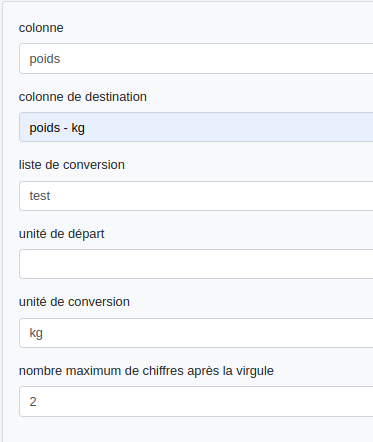
Colonne : colonne de départ.
Colonne de destination : colonne où le résultat de la conversion sera stocké.
Liste de conversion : liste utilisée pour la conversion.
Unité de départ : précise l’unité de départ si elle n’est pas présente dans la cellule d’origine. Elle ne doit contenir que le nombre et potentiellement l'unité (avant ou après).
Unité de conversion : l’unité souhaitée présente dans la liste de conversion.
Résultat :

voici le paramétrage pour exprimer le poids en kilogrammes :
Résultat :

# Correspondance
Cette opération permet de charger une table de correspondance, de sélectionner la (ou les) colonne(s) de correspondance entre le fichier d’origine et cette nouvelle table ainsi que les colonnes à ajouter issues de la table de correspondance.
Exemple :

Ici, nous importons le fichier “Nomenclature 2019”. Il comprend la colonne “Famille” déjà présente dans les données entrantes de l’étape. Nous souhaitons ajouter à nos données, la colonne “TYPE DE PRIX” uniquement présente dans la nomenclature. La colonne “Famille” sera notre colonne de correspondance. Elle devra s’écrire de la même façon que dans le fichier d’origine.

“Famille” est donc notre colonne de correspondance et nous ajoutons la colonne”TYPE DE PRIX” à notre fichier de travail.
Résultat :

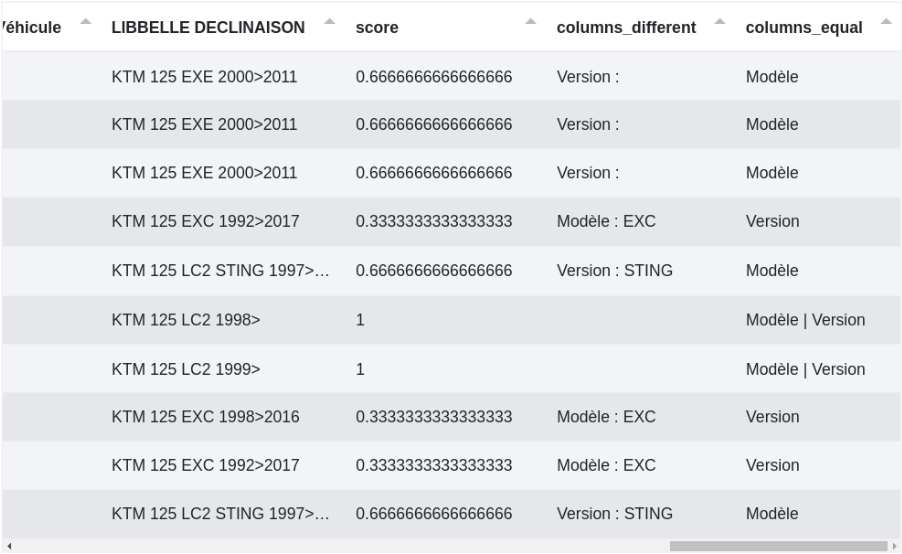
# Comparaison
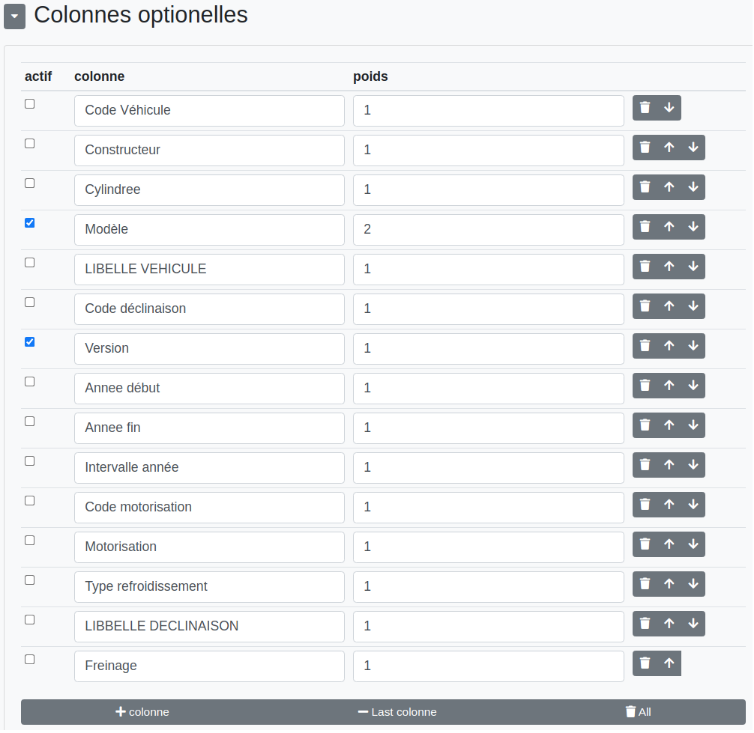
Une autre fonctionnalité de cette étape est de comparer les données entrantes avec le fichier importé dans l’étape. Il est toujours nécessaire d’avoir une ou plusieurs colonnes de correspondance et il est également possible d’ajouter des colonnes. En plus de ces colonnes de correspondance, peuvent s’ajouter une ou plusieurs colonnes optionnelles permettant d’affiner la comparaison.
Chaque ligne du fichier d’origine aura un score allant de “vide” à 1 :
- Vide : il n’y a pas de score car les colonnes de correspondance n’ont pas de matching.
- 0 : les colonnes de correspondance correspondent toutes mais aucune colonne optionnelle.
- Entre 0 et 1 : les colonnes de correspondance correspondent toutes mais pas toutes les colonnes optionnelles. Le score varie en fonction des poids des colonnes. (voir plus bas)
- 1 : c’est un matching parfait. Les colonnes de correspondance et optionnelles correspondent.
Nous prenons ici deux colonnes optionnelles avec des poids différents. Le modèle est plus important et a un poids de 2 tandis que la version a un poids de 1. Si seul, le modèle a une correspondance alors le score sera de 0,6666. Le score sera de 0,3333 dans le cas de la version.
Voici un exemple des données en sortie :
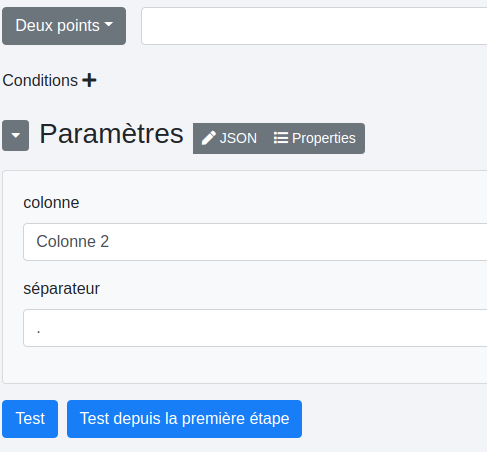
# Deux points
Cette étape sépare les couples “clé : valeur” d’une colonne cible (“Colonne 2” ici) pour créer une nouvelle colonne dont le nom sera la “clé” et le contenu la “valeur”. Le séparateur délimite les couples “clé : valeur” dans le cas où il y en aurait plusieurs dans la colonne cible.
Avant :

Après :

# Envoi de mail
Cette étape permet d’envoyer des mails à une liste d’adresses.
À partir de ces données initiales :

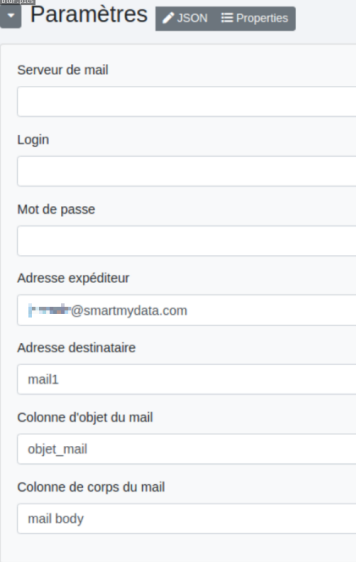
Serveur de mail : identifiant de serveur SMTP.
Login : login serveur SMTP.
Mot de passe : mot de passe du serveur SMTP.
Adresse expéditeur : une adresse mail d’expédition ou la colonne regroupant les adresses des expéditeurs.
Adresse destinataire : une adresse mail de destination ou la colonne regroupant les adresses des destinataires.
Colonne d’objet du mail : comme son nom l’indique, il s’agit de la colonne regroupant les objets des mails.
Colonne de corps de mail : la colonne des corps de mails.
Voici le mail généré :
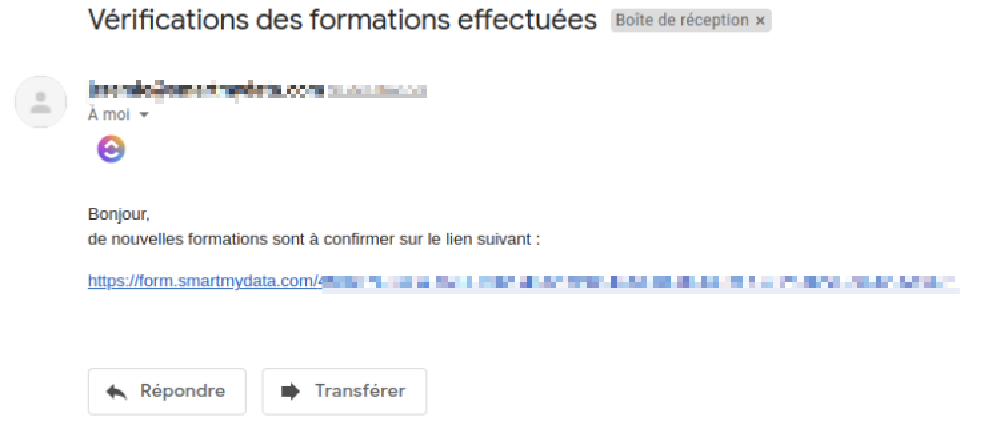
Trois champs sont nécessaires si vous souhaitez utiliser votre propre service mail comme Mailgun ou Mailjet : "serveur de mail", "login" et "mot de passe".
Prenons le cas de Mailjet.
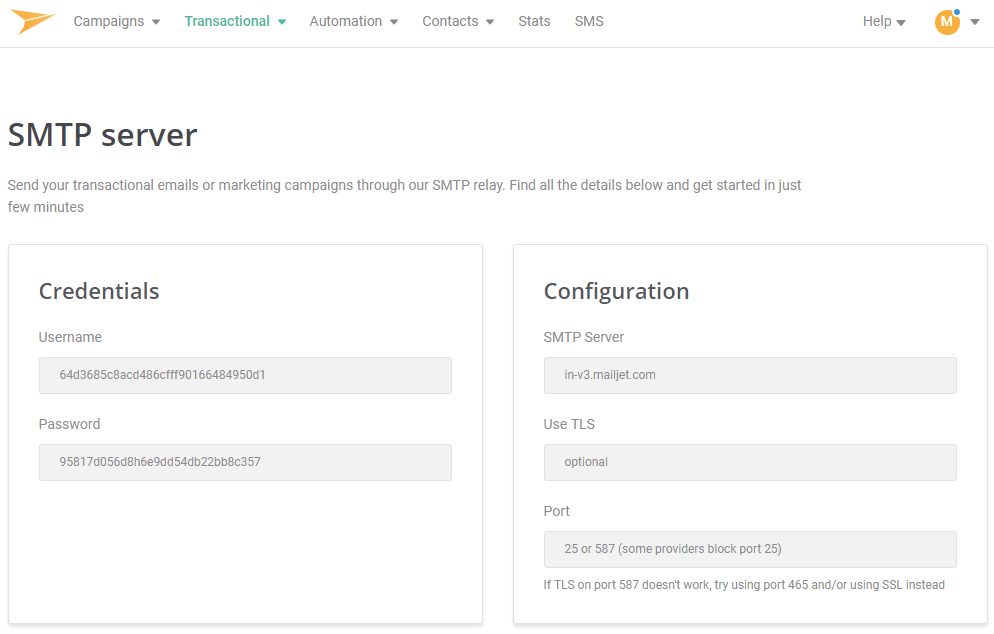
Le SMTP Server devra être inséré dans le champ "Server de mail", Username dans "Login" et Password dans "Mot de passe".
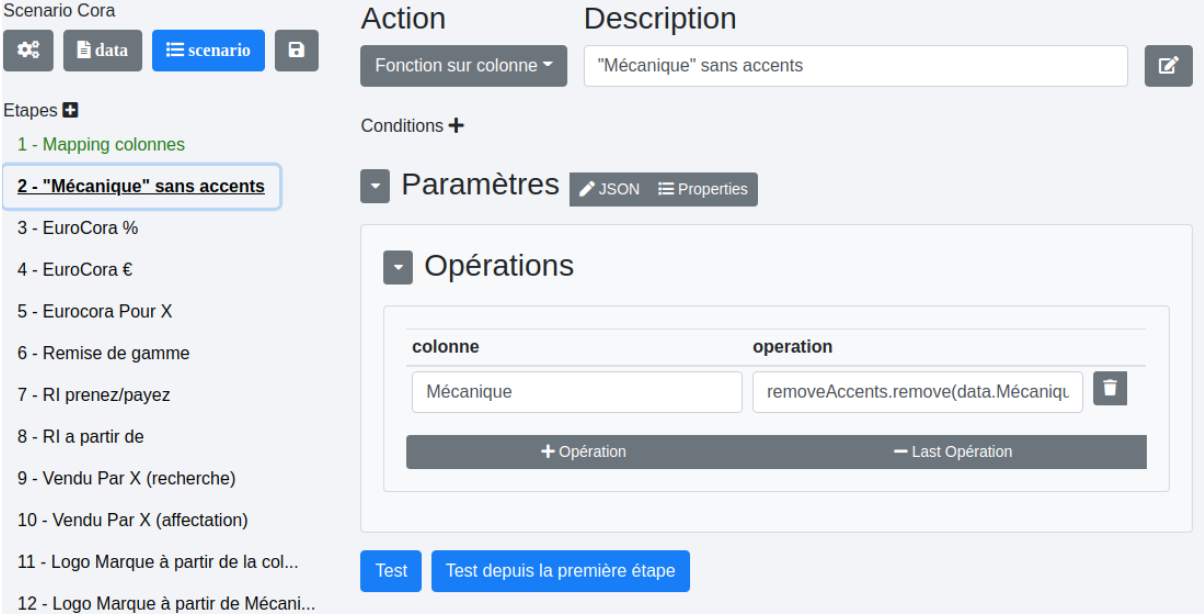
# Fonction sur colonne
Cette opération permet d’utiliser des fonctions sur une colonne complète. Elle nécessite des connaissances en JavaScript. Des fonctions seront créées à la demande.
Voici quelques exemples d’actions :
- uuid : crée une uuid;
- id : crée une id démarrant à 0;

On remplace "Oui" par un "x" ou on efface le contenu dans le cas contraire.

Avant :

Après :
On ajoute la mention “Alcool” dans la colonne “Mention légale” si la colonne “Alcool” est à “Oui”.

Avant :

Après :
On efface le symbole "%".

Avant :

Après :

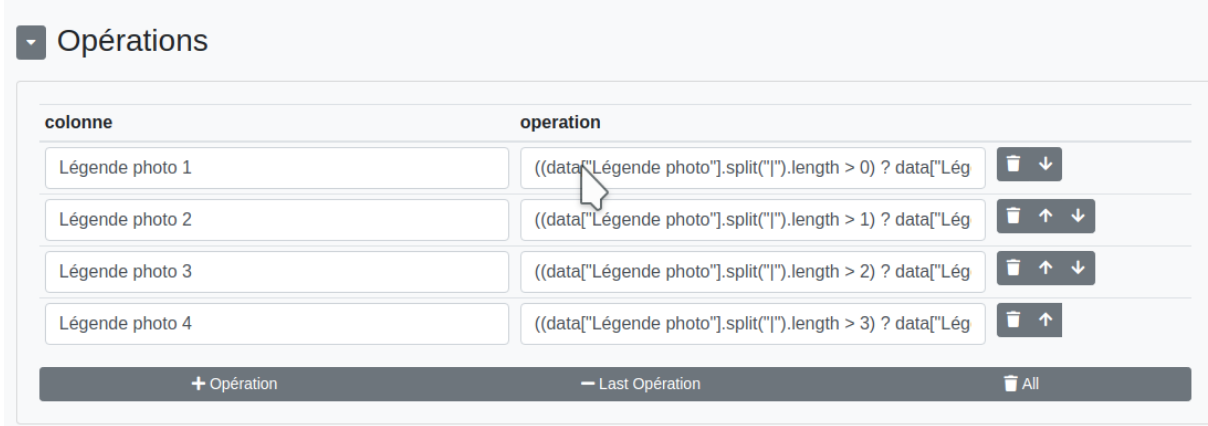
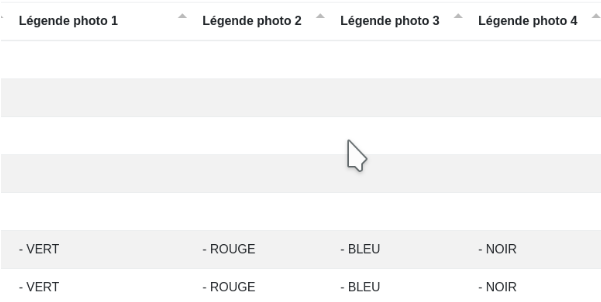
Répartir plusieurs données dans plusieurs colonnes. Voici le code JavaScript complet : ((data["Légende photo"].split("|").length > 0) ? data["Légende photo"].split("|")[0] : "")
Avant :

Après :
Séparer nombres et unités.


# Fonctions Excel (en cours d’écriture)
L’objectif de ce module est de vous faciliter la vie dans le traitement de vos tableurs en vous apportant des fonctions similaires à ce qu’on trouve dans Excel mais en plus simple d’utilisation. L’étape "Fonctions Excel" peut parfaitement contenir plusieurs fonctions s’enchaînant les unes après les autres.
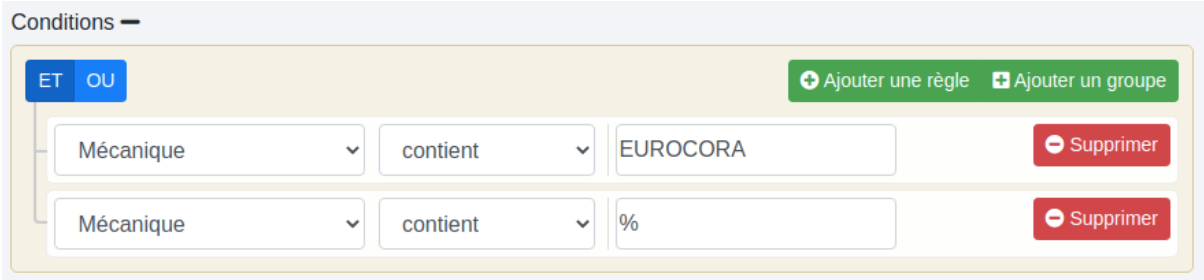
# Conditions
Vous pouvez choisir d’activer certaines fonctions de manière conditionnelle. Ces conditions concernent alors toutes les fonctions de l’étape. Pour réaliser des actions sur d’autres conditions ou sur le fichier complet, ajouter une nouvelle étape.
Par exemple ici, je souhaite exécuter des fonctions sur les lignes concernant uniquement M Brandon Gois.
J’ouvre le constructeur de requêtes en cliquant sur  . Le constructeur apparaît.
. Le constructeur apparaît.

Je sélectionne la colonne des noms.
Elle doit avoir la valeur "GOIS".

Le nom ne suffisant pas, il me faut ajouter une autre condition sur la colonne des prénoms avec ce bouton :  .
.

Je choisis la colonne des prénoms qui doit avoir la valeur "BRANDON".

Ici, les deux conditions sur les noms et les prénoms doivent être vérifiées simultanément. C’est pourquoi,le "et" doit être choisi (bleu foncé) :  .
.
Rendez-vous ici pour en savoir plus sur le constructeur de requêtes.
# Présentation d’une fonction type
Voici une fonction type :
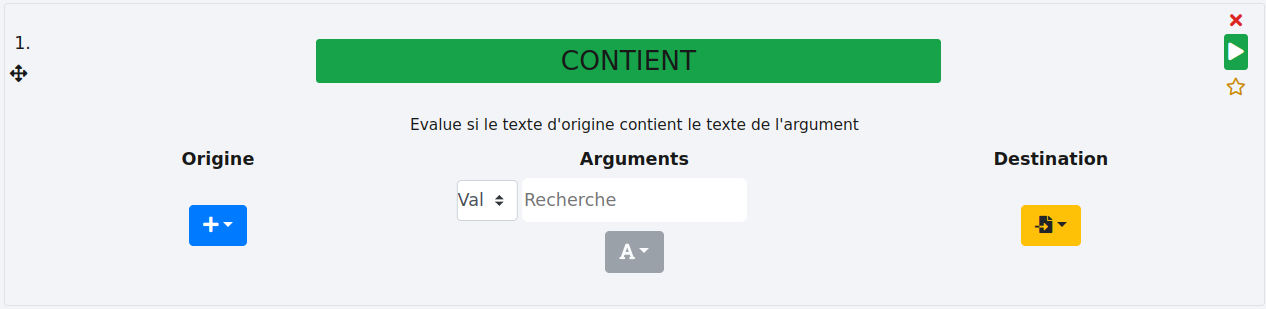
Elle comporte :
- un nom :

- une descriptiion succinte :

- une ou plusieurs colonnes d’origine :

Il s’agit là de la colonne à traiter. Certaines fonctions peuvent en accepter plusieurs. - d’éventuels arguments :

Certaines fonctions prennent un ou plusieurs arguments, optionnels ou pas. Ici, la fonction nécessite de préciser l’expression recherchée dans la colonne d’origine. - types d’arguments :

Certaines fonctions permettent de sélectionner un type d’argument entre "val" (pour entrer une valeur) et "Col" pour entrer le nom d’une colonne pré-existante. C’est particulièrement utile si vous souhaitez copier ou rechercher le contenu d’une colonne dans une autre par exemple. Dans le cas d’une colonne, le menu est dynamique et affiche les colonnes possibles.
- une colonne de destination :

Il s’agit là de la colonne de sortie dans laquelle le résultat de la fonction sera stocké. Selon vos cas d’usage, elle n’est pas obligatoire.
# Fonctionnalités génériques
# Ajouter une fonction
Il suffit de cliquer sur ce bouton  pour faire apparaître le menu déroulant des fonctions et faire votre choix.
pour faire apparaître le menu déroulant des fonctions et faire votre choix.
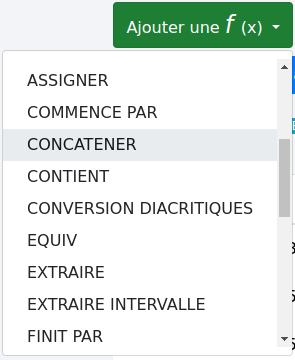
Votre nouvelle fonction apparaît alors (voir Déplacement pour aller plus loin).
# Favoris
Vous pouvez ajouter une fonction à vos "favoris" en cliquant sur l’étoile en haut à droite.

Une fois fait, la fonction apparaîtra en haut du menu déroulant des fonctions, facilitant son accès. Par exemple, je souhaite mettre la fonction "ASSIGNER" en favoris.

Je clique sur l’étoile et la fonction apparaît en haut du menu déroulant dans la section "Favoris".
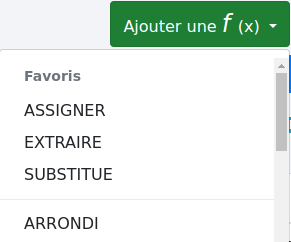
Cliquer de nouveau sur l’étoile retire la fonction des favoris.
# Sélectionner une colonne, un argument ou une destination (et les déselectionner)
# Code
En bas de l’encadré de chaque fonction apparaît le code JavaScript correspondant à la fonction.
# Test
Le bouton  permet de tester l’étape dans sa globalité. Si elle comporte plusieurs fonctions, toutes seront testées.
permet de tester l’étape dans sa globalité. Si elle comporte plusieurs fonctions, toutes seront testées.
# Test d’une fonction spécifique
Il peut être utile de tester une fonction en cliquant sur le bouton "play" en haut à droite :  . Dans ce cas, les fonctions la précédant seront exécutées et le traitement s’arrêtera à cette dernière fonction. Le résultat apparaîtra dans l’encadré de la fonction choisie.
. Dans ce cas, les fonctions la précédant seront exécutées et le traitement s’arrêtera à cette dernière fonction. Le résultat apparaîtra dans l’encadré de la fonction choisie.
# Déplacement
Dans le cas où vous avez plusieurs fonctions dans la même étape, vous pouvez déplacer une fonction grâce à ce bouton :  . Il vous suffit alors de glisser/déposer la fonction où vous voulez.
. Il vous suffit alors de glisser/déposer la fonction où vous voulez.
# ARRONDI
Cette fonction arrondit un nombre décimal à l’entier le plus proche. Attention à ce que le point remplace la virgule! Il nous faut "9.2" et non "9,2".
Prenons l’exemple d’un fichier contenant cette colonne "valeurs" sur laquelle nous allons appliquer la fonction "ARRONDI".

Nous sélectionnons la colonne "valeurs" en "Origine" et stockons les nouvelles valeurs dans la colonne de destination "valeurs_arrondies" puis testons la fonction.


Vous pouvez directement modifier la colonne d’origine, dans ce cas, inutile de préciser la destination.


# ARRONDI.INF
Cette fonction est identique à "ARRONDI" à ceci près qu’elle arrondit un nombre décimal à l’entier inférieur. Attention à ce que le point remplace la virgule! Il nous faut "9.2" et non "9,2".
En reprenant l’exemple de la fonction "ARRONDI" au-dessus, nous obtenons ceci :


Comme pour la fonction "ARRONDI", vous pouvez modifier directement la colonne d’origine.


# ARRONDI.SUP
Cette fonction est identique à "ARRONDI" à ceci près qu’elle arrondit un nombre décimal à l’entier supérieur. Attention à ce que le point remplace la virgule! Il nous faut "9.2" et non "9,2".
En reprenant l’exemple de la fonction "ARRONDI" au-dessus, nous obtenons ceci :
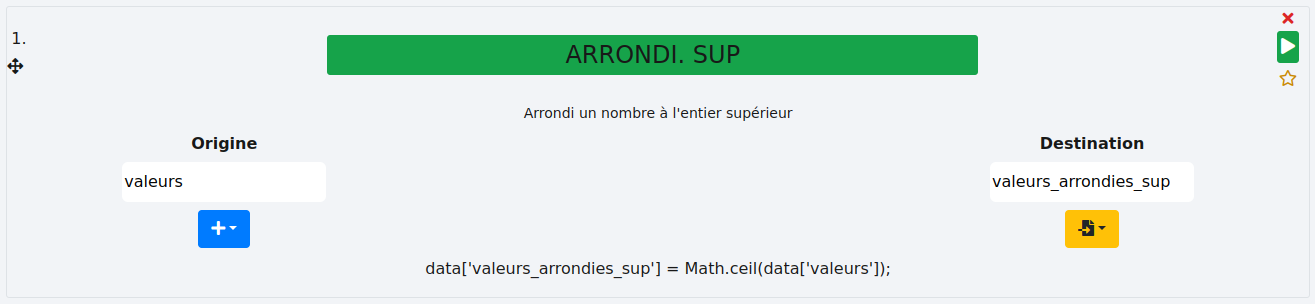

Comme pour la fonction "ARRONDI", vous pouvez modifier directement la colonne d’origine.


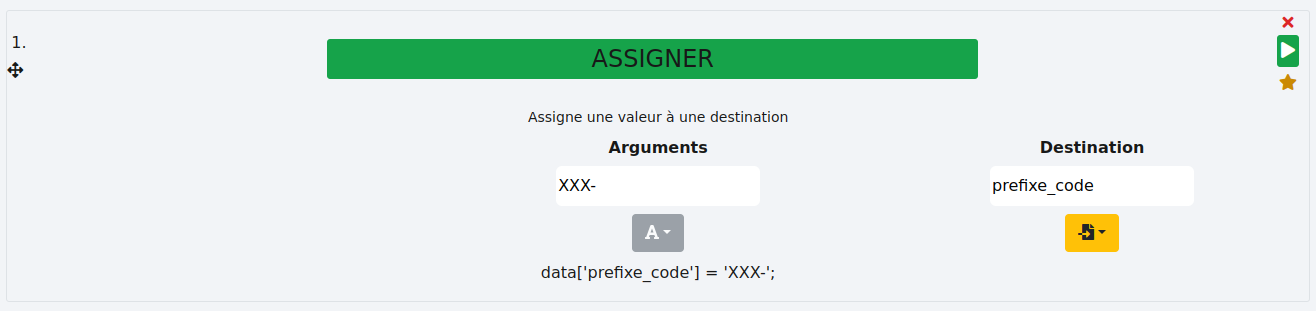
# ASSIGNER
Cette fonction permet d’assigner une valeur à une ou plusieurs colonnes.
- Colonne vide :
Vous pouvez créer une ou plusieurs colonnes vides. Pour ce faire, cliquez sur l’icône de destination et sélectionnez "Nouvelle coloenne" pour y entrer le nom de la nouvelle colonne.


Vous pouvez également créer plusieurs colonnes vides en une seule opération.


- Colonne non vide :
Vous pouvez créer une ou plusieurs colonnes avec des valeurs fixes non vides.

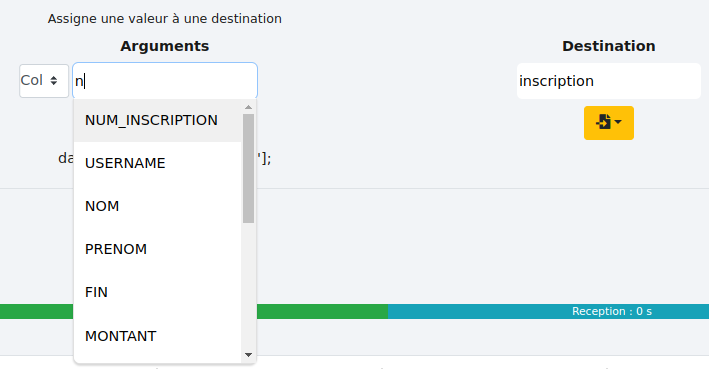
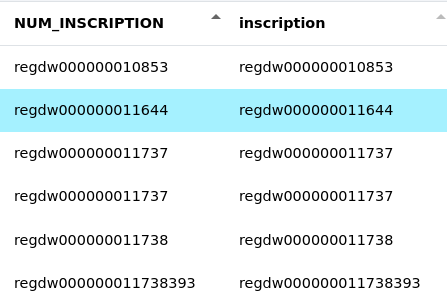
- Copier une colonne :
Il est également possible de dupliquer une colonne. Pour ce faire, sélectionnez l’option "Col" dans les types d’arguments puis entrez le nom de la colonne à copier et enfin entrez le nom de la colonne où vous souhaitez copier le contenu.
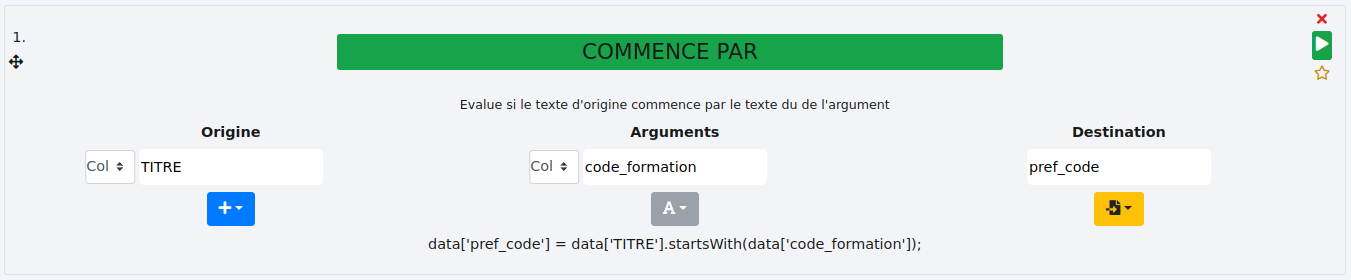
# COMMENCE PAR
Cette fonction détermine si une cellule commence par l’expression recherchée et affiche un statut - "true" si oui, "false" si non - dans la colonne de destination.
- Une valeur :
Nous cherchons à savoir quelles cellules ont un n°ALCOR commençant par "N".



- Une colonne :
Il est également possible de rechercher le contenu d’une colonne pré-existante dans une autre colonne grâce à l’option "Col" dans les arguments.
# CONCATENER
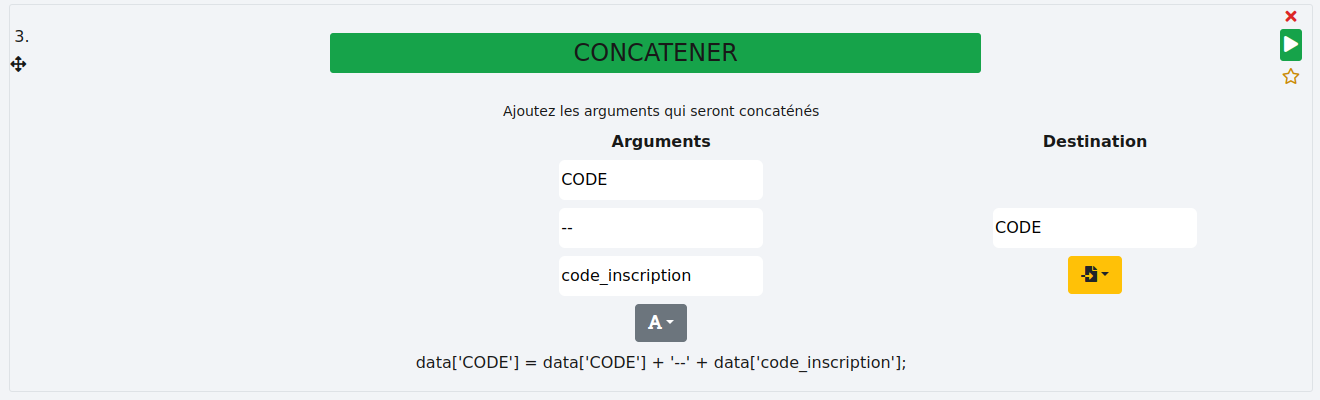
Cette fonction permet de concaténer une ou plusieurs colonnes entre elles en y ajoutant éventuellement des termes supplémentaires.
- Exemple :
Nous souhaitons concaténer les colonnes "CODE" et "code_inscription" en les séparant par deux tirets "--" dans un champ libre. Le résultat sera stocké dans la colonne "CODE" et non dans une nouvelle colonne.

Ce qui nous donne cette fonction et son résultat :

# CONTIENT
Cette fonction permet de savoir si une colonne contient une expression (qui peut être le contenu d’une colonne grâce à l’option "Col" des arguments) et renvoie un statut (true/false) dans une colonne de destination.
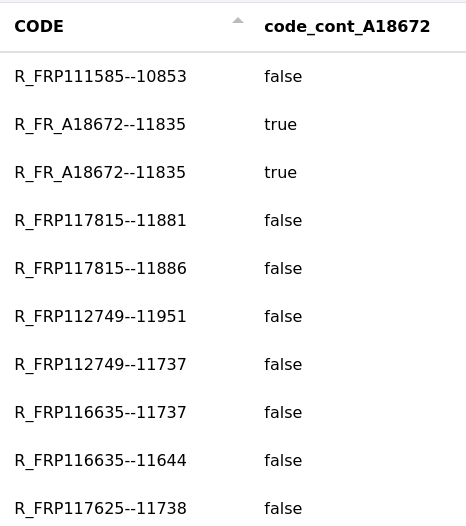
Exemple 1 - valeur :
Nous souhaitons savoir si la colonne "CODE" contient l’expression "A18672". Nous stockons le résultat dans une nouvelle colonne nommée "code_cont_A18672".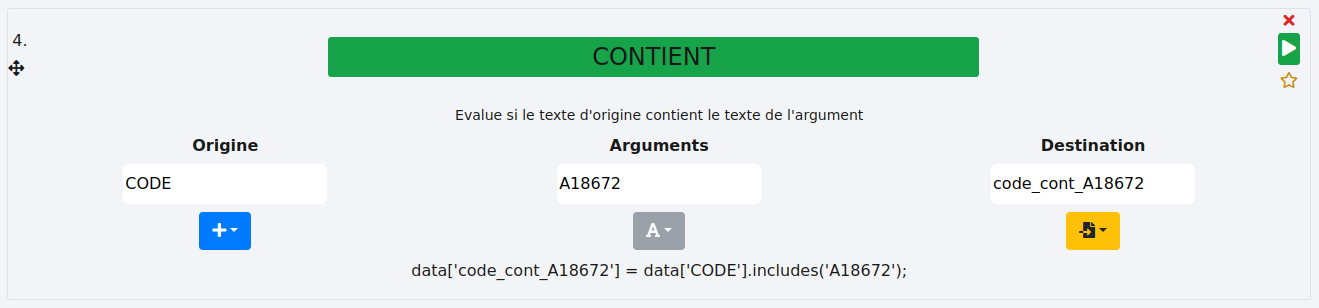
Résultat :
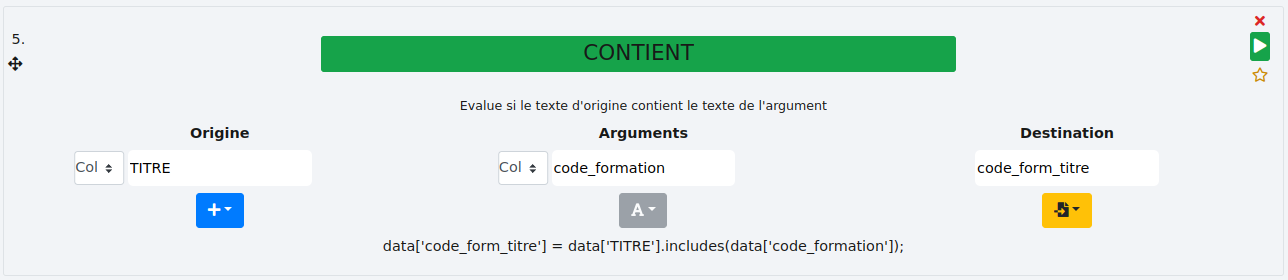
Exemple 2 - colonne :
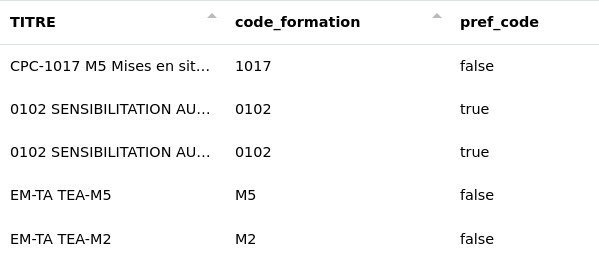
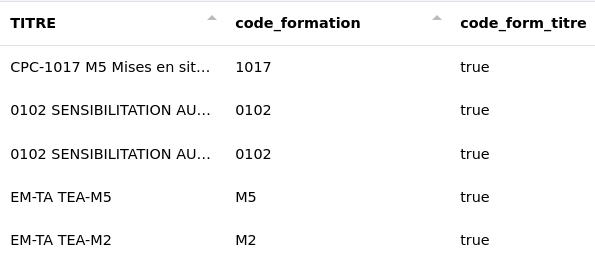
Il est aussi possible de rechercher le contenu d’une colonne dans une autre. Ici, nous recherchons le contenu de la colonne "code_formation" dans la colonne "TITRE". Le résultat est stocké dans la colonne "code_form_titre".
# CONVERSION DIACRITIQUES
Il s’agit ici de remplacer les caractères spéciaux comme le "ç" ou les caractères accentués par leurs équivalents "standards". Le "ç" deviendra "c" par exemple.
- Exemple :
Nous voulons retirer les diacritiques des prénoms afin de les uniformiser.

Il nous est inutile de stocker le résultat dans une nouvelle colonne, c’est pourquoi il n’y a pas de destination.

La colonne est retournée ainsi :

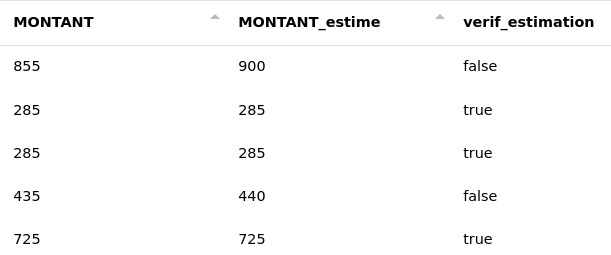
# EQUIV
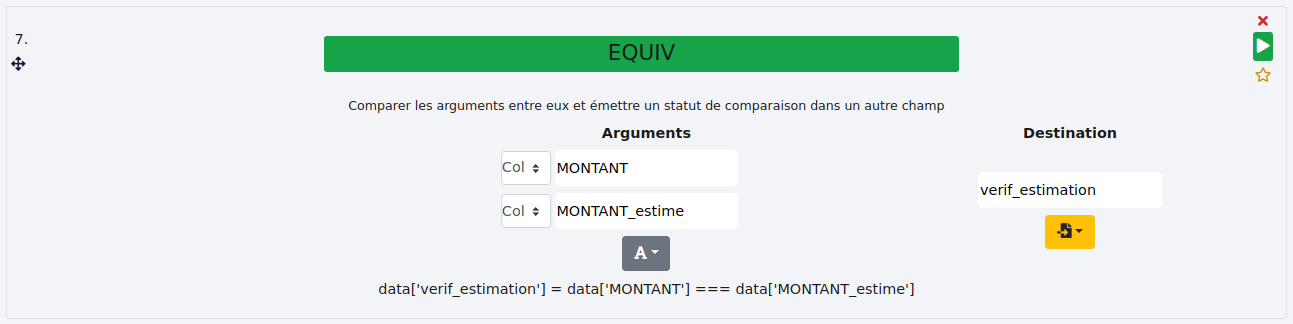
Cette fonction permet de déterminer si les contenus de deux colonnes sont identiques et renvoie un statut dans une nouvelle colonne.
Colonnes :
Ici, nous souhaitons déterminer si nos estimations de coûts sont justes. Pour ce faire, nous comparons les contenus des colonnes "MONTANT" et "MONTANT_estime". Le résultat est stocké dans la colonne "verif_estimation".
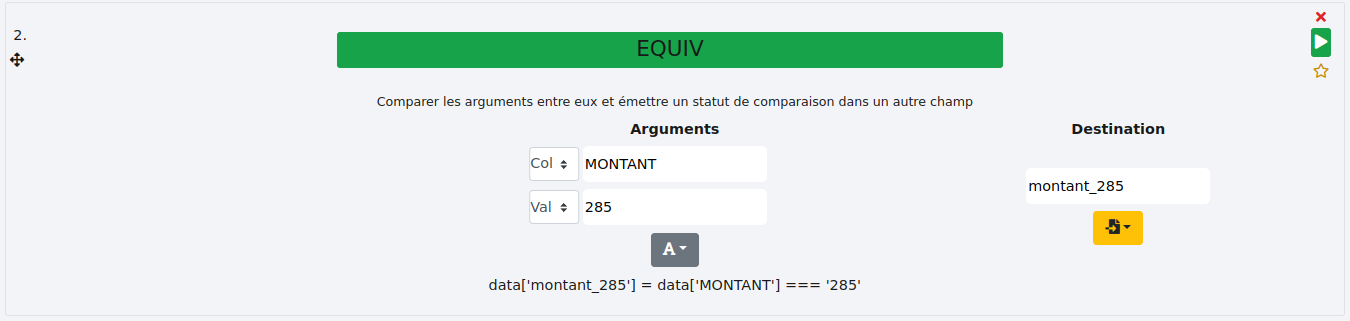
Valeur :
Il est également possible de comparer une colonne et une valeur fixe. Par exemple, vous souhaitez connaître quelles lignes ont un montant de 285€.

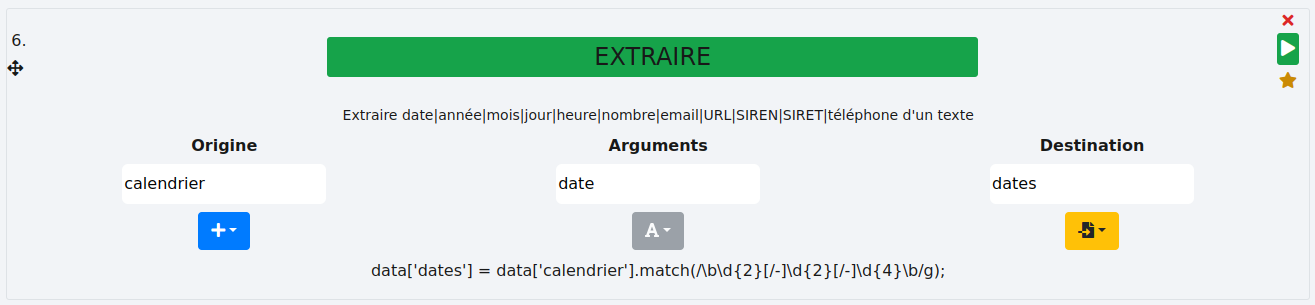
# EXTRAIRE
Cette fonction extrait des expressions de différents types au sein d’un texte plus important comme des dates, des url ou encore des numéros de téléphone. Le type doit être précisé lors de l’extraction.
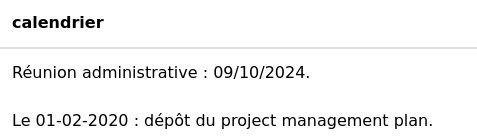
# Date
Nous cherchons à extraire les dates de la colonne "calendrier" et à les stocker dans une nouvelle colonne "dates".

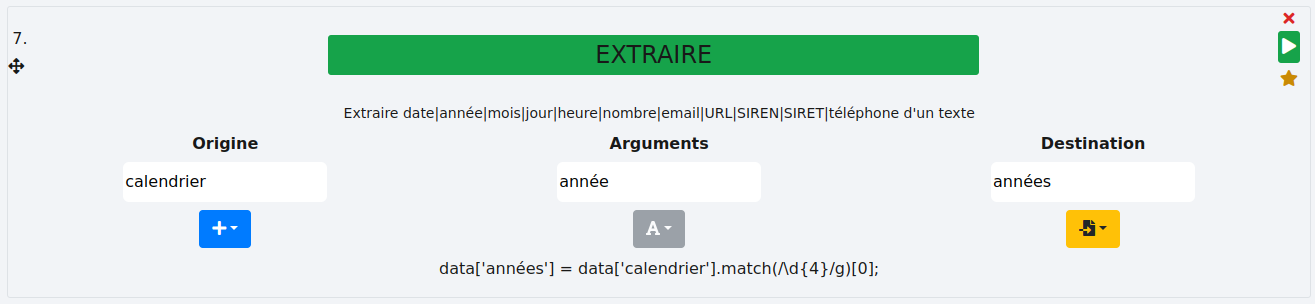
# Année
Nous allons isoler les années du calendrier pour les stocker dans une nouvelle colonne "années". Nous partons de la colonne "calendrier" comme précédemment.

# Mois
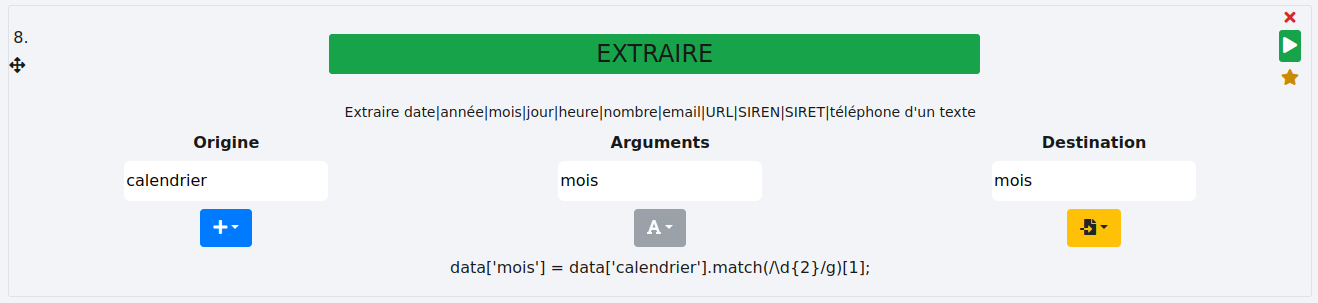
Ici, nous allons extraire les mois de la colonne "calendrier" et les stocker dans nouvelle colonne "mois".

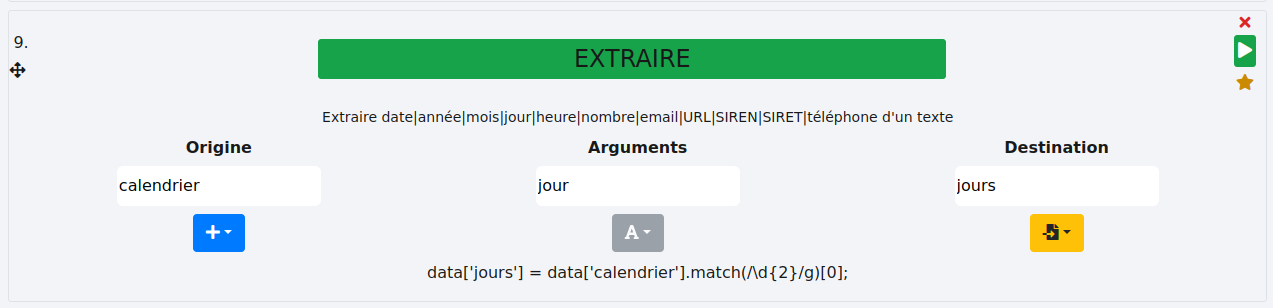
# Jours
Sur le même principe que les fonctions plus haut, l’idée est de récupérer le jour dans une date au format 09/11/2024 ou 09-11-2024. À partir de la colonne calendrier, nous allons récupérer les jours et les stocker dans une nouvelle colonne "jours".

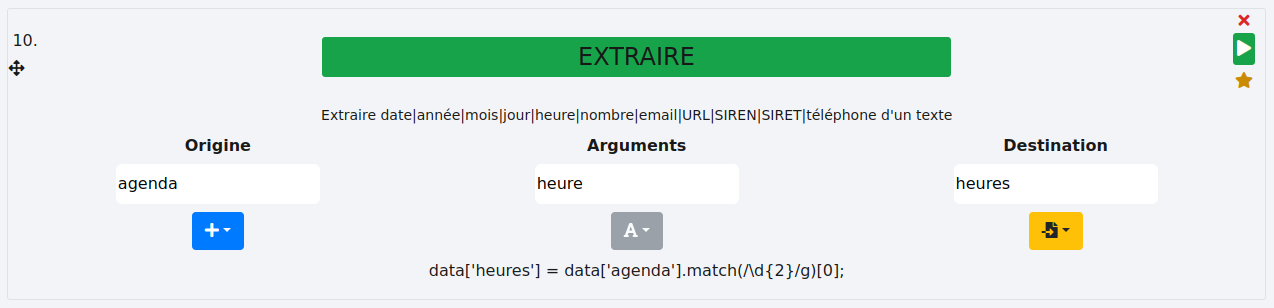
# Heure
Il s’agit de récupérer les heures. Sur un modèle "12:45", "12" sera extrait. Voyons en exemple avec la colonne "agenda". Les heures seront stockées dans une nouvelle colonne "heures".


# Nombre
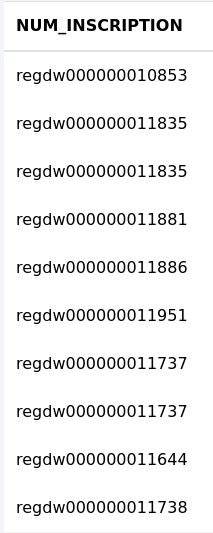
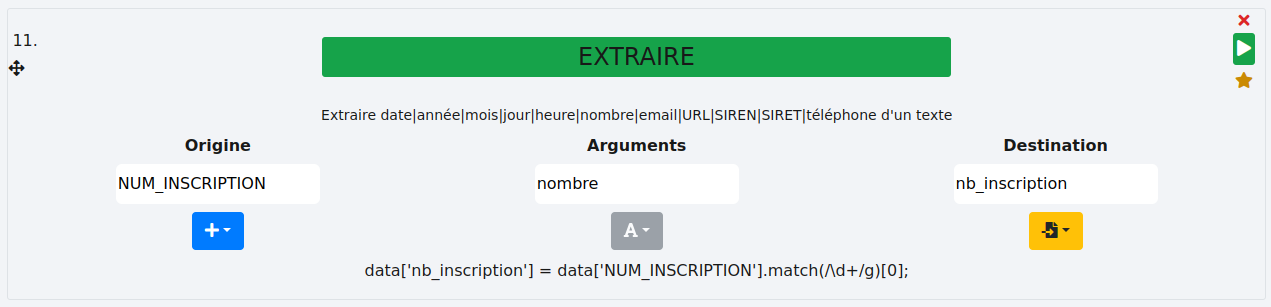
Cette fonction extrait les chiffres d’une colonne. Voyons un exemple avec la colonne "NUM_INSCRIPTION". Le résultat sera stocké dans une nouvelle colonne "nb_inscription".

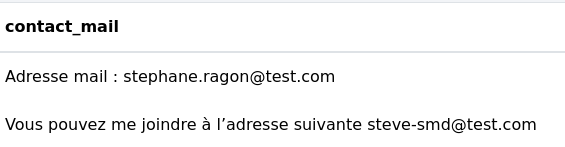
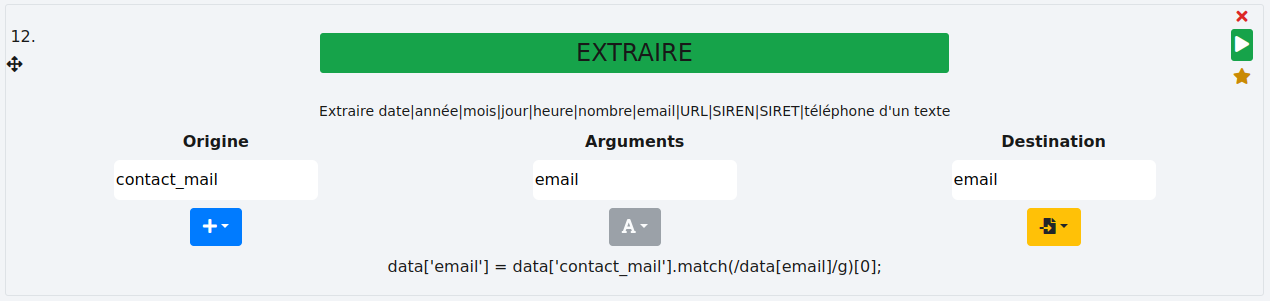
Cette fonction extrait les adresses mails d’une colonne. Dans l’exemple suivant, nous extrayons les adresses mails de la colonne "contact_mail" pour les stocker dans une nouvelle colonne "email".

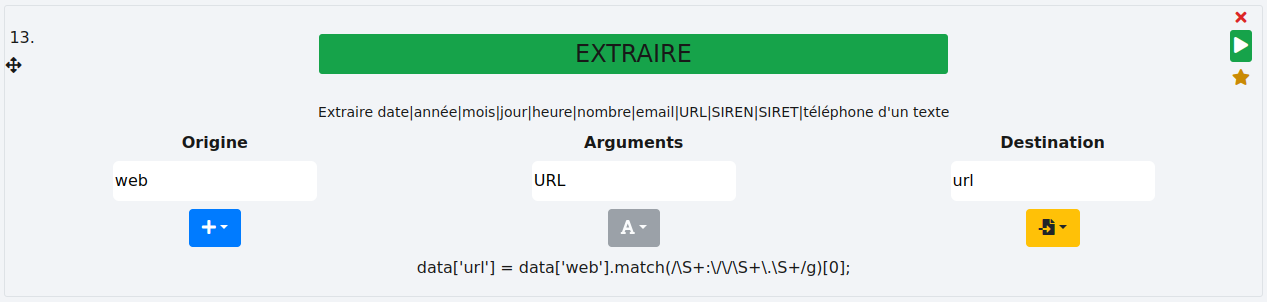
# URL
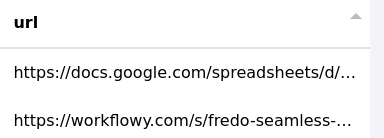
L’objectif est ici de récupérer des url dans un texte. Dans l’exemple suivant, nous extrayons les url de la colonne "web" pour les mettre dans la nouvelle colonne "url".

# SIREN
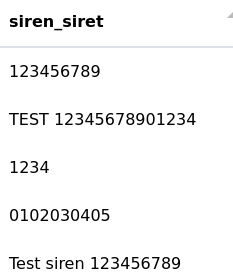
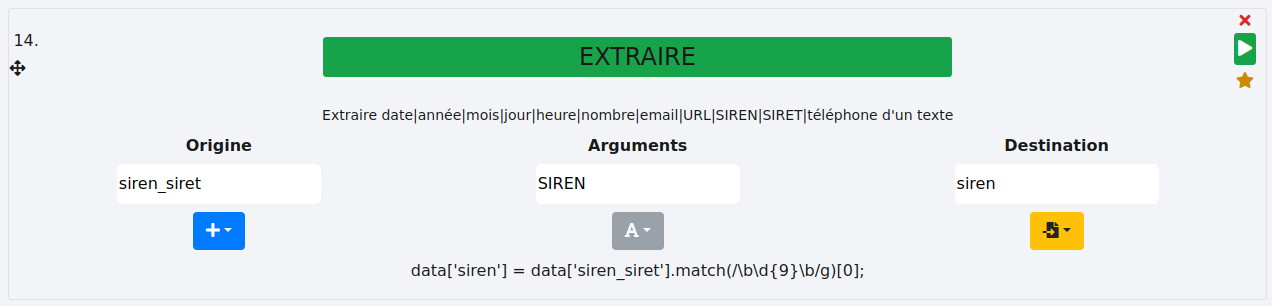
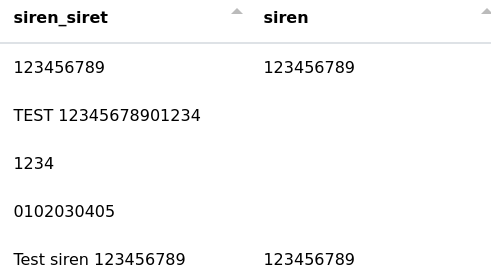
Le but est d’extraire le n° SIREN (série de 9 chiffres) d’une cellule. Dans notre exemple, la colonne "siren_siret" contient des séries plus courtes mais aussi plus longues (n° SIRET). Seuls les n°SIREN à 9 chiffres seront récupérés et placés dans la nouvelle colonne "siren".
# SIRET
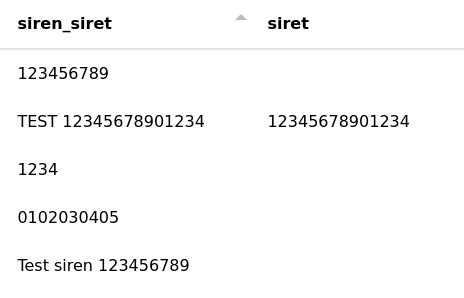
En complément du n° SIREN, nous avons également la possibilité de récupérer son pendant, le n° SIRET à 14 chiffres. Nous reprenons notre colonne contenant à la fois des n° SIREN et SIRET et extrayons les SIRET pour les stocker dans une nouvelle colonne "siret".

# Téléphone
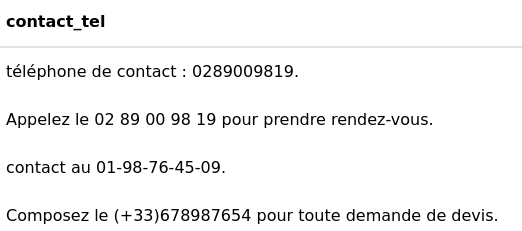
Cette fonction a pour but d’extraire un n° de téléphone d’une cellule.

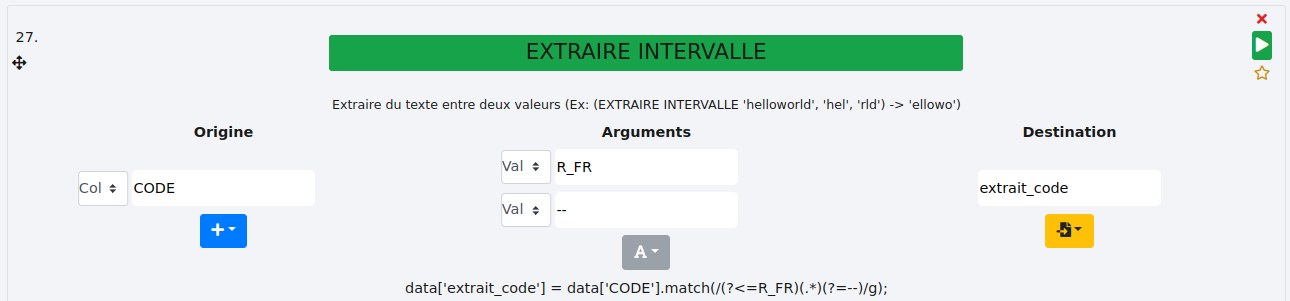
# EXTRAIRE INTERVALLE
Cette fonction permet d’extraire une expression entre deux bornes pouvant être n’impporte quels caractères, des mots, des chiffres ou encore les contenus de deux colonnes grâce à l’option "Col" des arguments.
Valeur :
Nous cherchons à extraire les caractères entre les expressions suivantes "R_FR" et "--" au sein de la colonne "CODE". Le résultat est stocké dans une nouvelle colonne "extrait_code".

Colonne :
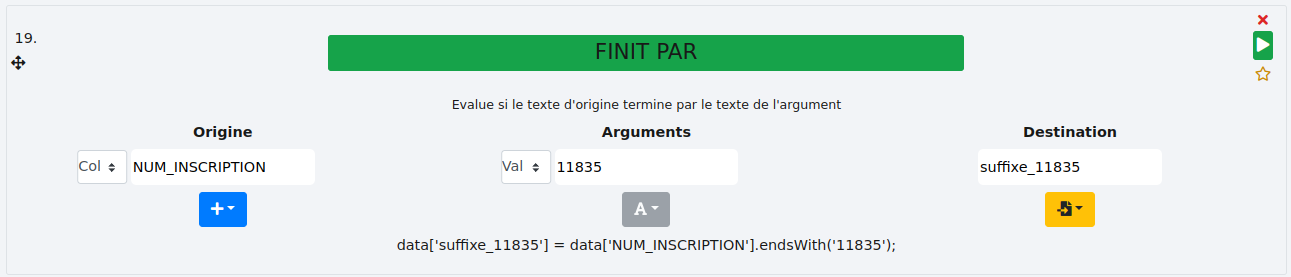
# FINIT PAR
Cette fonction permet de déterminer si le contenu d’une cellule se termine par l’expression recherchée et renvoie un statut dans une nouvelle colonne. L’expression recherchée peut être le contenu d’une colonne grâce à l’option "Col" des arguments.
Valeur :
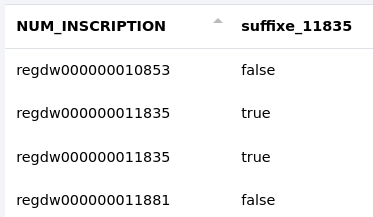
Nous allons ici rechercher les cellules se terminant par "11835" dans la colonne "NUM_INSCRIPTION" et stocker le résultat dans la nouvelle colonne "suffixe_11835".
Colonne :
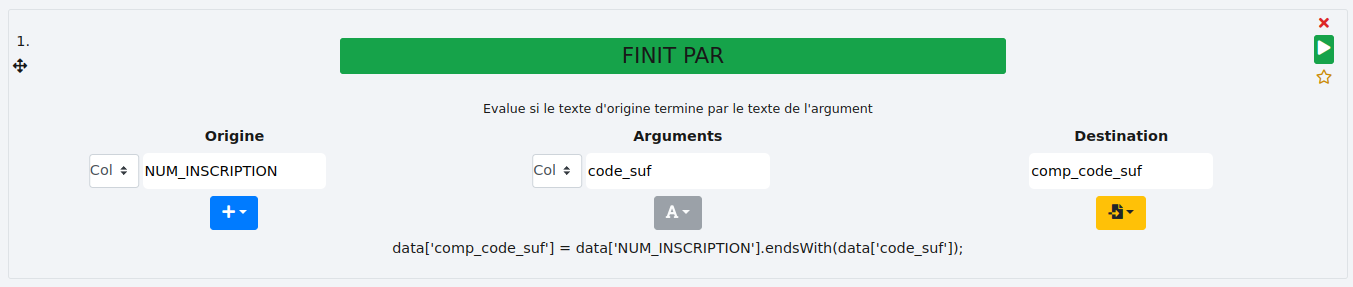
Il est possible de vérifier si les cellules se terminent par le contenu d’une colonne comme ici où nous comparons la colonne "NUM_INSCRIPTION" avec la colonne "code_suf".
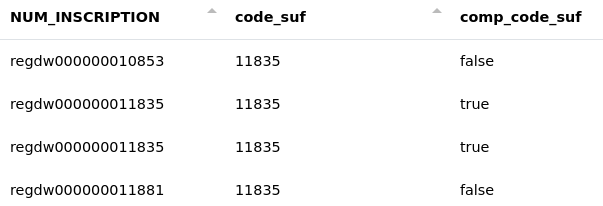
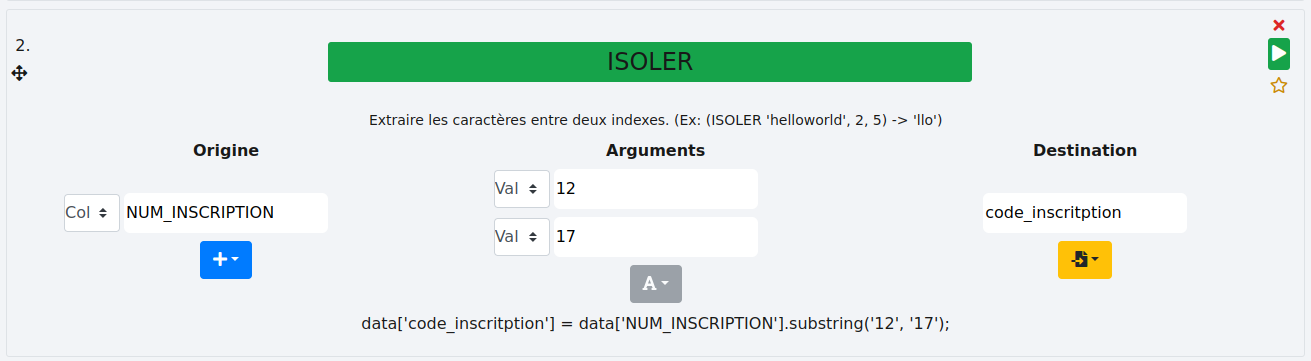
# ISOLER
Cette fonction permet d’extraire une expression entre deux bornes qui sont ici les index des caractères de la cellule (1 à n). Il faut pour cela indiquer l’index du caractère précédent le premier caractère à récupérer (x) et l’index du dernier caractères à récupérer (y). Ce qui pourrait se noter ainsi ]x,y]. Ces index peuvent être des valeurs fixes (option "Val") ou dépendrent des lignes (option "Col").
Valeur :
Dans cet exemple, nous voulons isoler les 5 derniers chiffres des cellules de la colonne "NUM_INSCRIPTION" et les stocker dans une nouvelle colonne nommée "code_inscription". Cela donne cet intervalle]12,17].
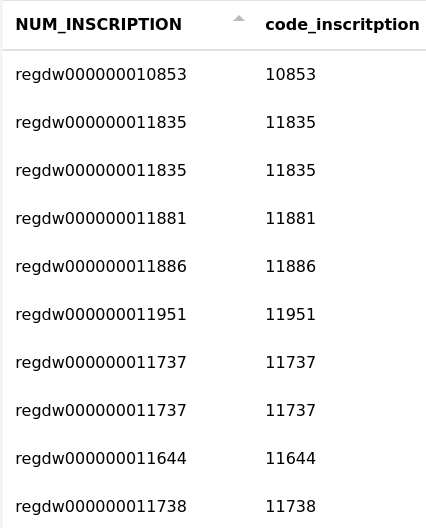
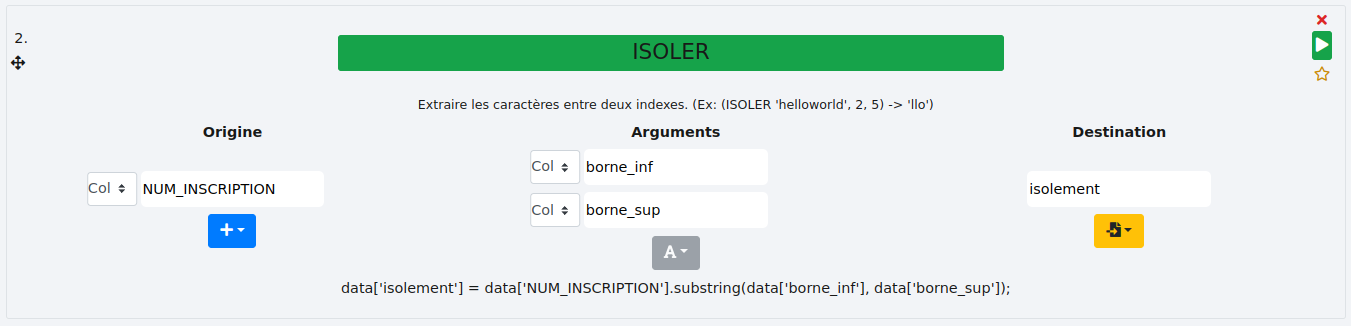
Colonne :
Supposons que nous avons deux colonnes indiquant les bornes inférieures et supérieures de l’intervalle d’isolement. Il nous suffit alors de les sélectionner dans les arguments pour récupérer les informations comme ici avec les colonnes "borne_inf" et "borne_sup".

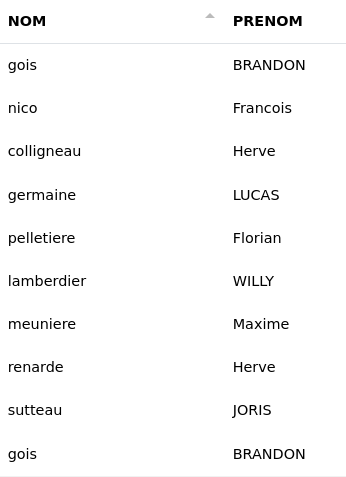
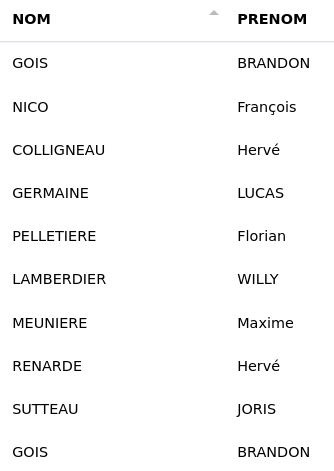
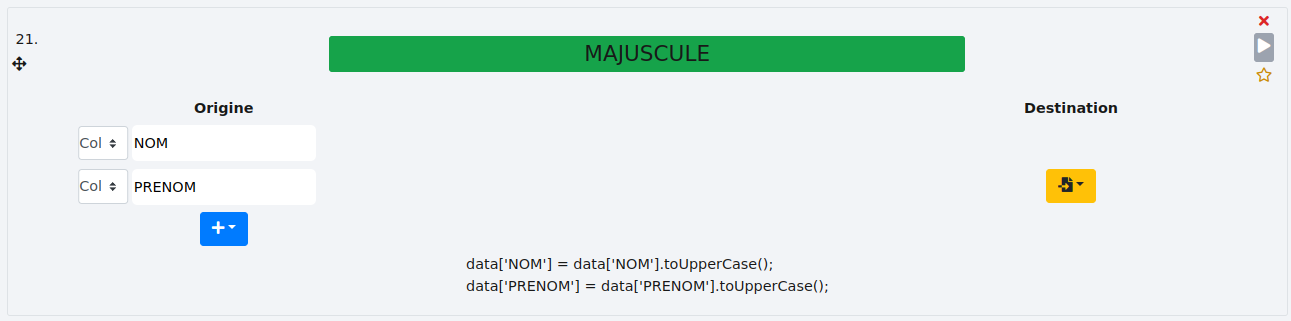
# MAJUSCULE
Cette fonction passe le contenu d’une ou plusieurs colonnes en majuscules.
Une colonne :
Ici, nous passons le contenu de la colonne "prenom" en majuscules pour les normaliser. Il n’y a pas de colonne de destination car nous voulons modifier directement la colonne "prenom".



Plusieurs colonnes :
Dans le cas où nous aurions plusieurs colonnes à passer en majuscules, il nous suffit de les sélectionner de cette manière :
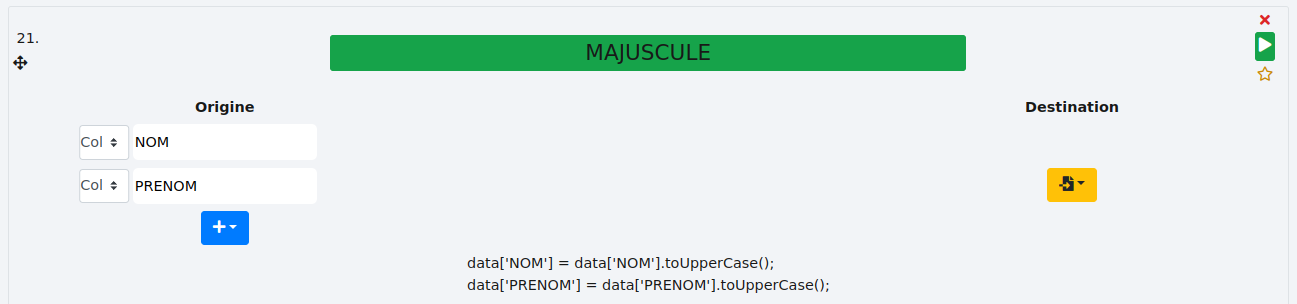
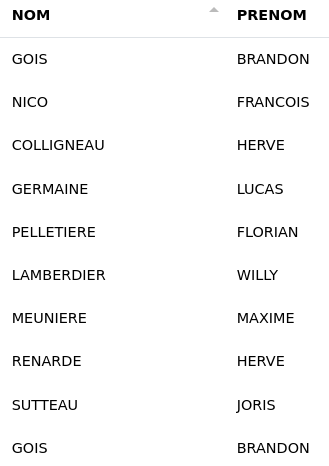
# MINUSCULE
L’inverse de la fonction MAJUSCULE. Elle passe le contenu d’une ou plusieurs colonnes en minuscules.
Une colonne :
Ici, nous passons le contenu de la colonne "prenom" en minuscules pour les normaliser. Il n’y a pas de colonne de destination car nous voulons modifier directement la colonne "prenom".


Plusieurs colonnes :
Dans le cas où nous aurions plusieurs colonnes à passer en minuscules, il nous suffit de les sélectionner de cette manière :

# NBCAR
Cette fonction compte le nombre de caractères des cellules de la colonne spécifiée et les retourne dans une nouvelle colonne.
- Exemple :
Nous cherchons à connaître le nombre de caractères des cellules de la colonne "TITRE". Le résultat est stocké dans la nouvelle colonne "nb_titre".



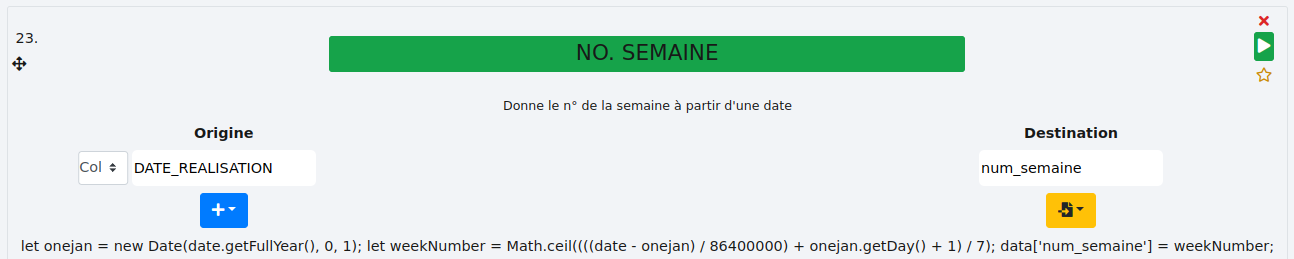
# N0.SEMAINE
Cette fonction renvoie le numéro de la semaine de l’année à partir d’une date.
- Exemple :
Ici, nous souhaitons récurérer le numéro de la semaine où la formation a été réalisée à partir de la colonne "DATE_REALISATION". Le résultat sera stocké dans une nouvelle colonne "num_semaine".


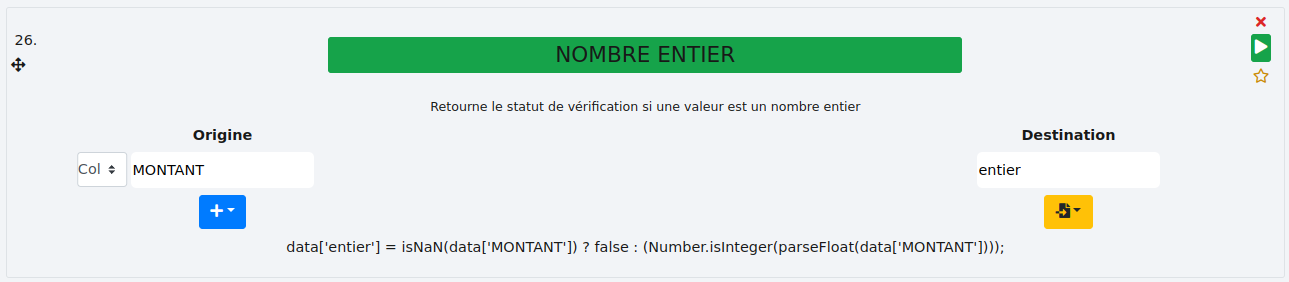
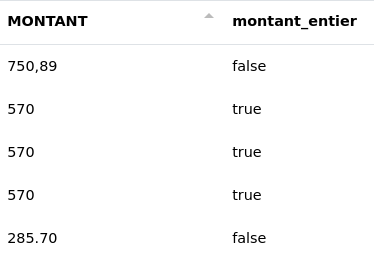
# NOMBRE ENTIER
Cette fonction détermine si le contenu des cellules d’une colonne est un nombre entier ou pas et émet un statut dans une nouvelle colonne.
- Exemple :
Nous voulons savoir si les montants sont bien des nombres entiers. Le résultat sera stocké dans une nouvelle colonne "montant_entier".
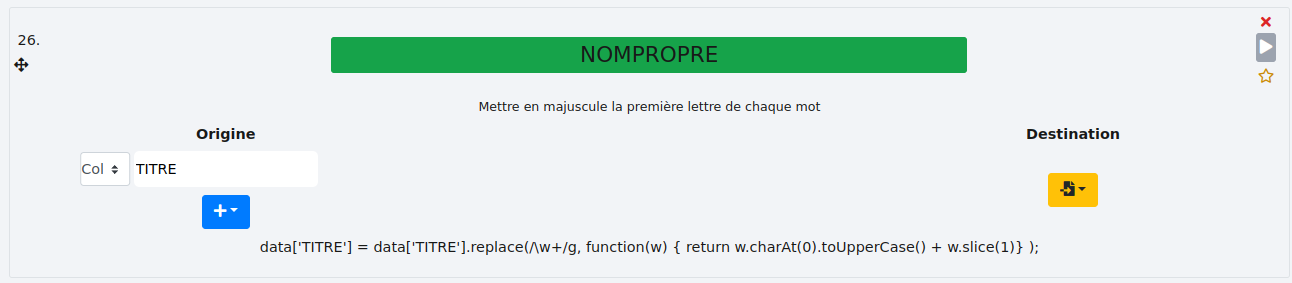
# NOM PROPRE
Cette fonction passe la première lettre de chaque mot des cellules de la ou des colonnes sélectionnées en majuscule.
- Exemple :
Nous voulons passer la première lettre de chaque mot de la colonne "TITRE" en majuscule.


# NOM PROPRE2
Cette fonction passe la première lettre de chaque phrase des cellules de la ou des colonnes sélectionnées en majuscule.
- Exemple :
L’objectif est ici de mettre une majuscule sur la première lettre de chaque phrase de la colonne "informations". N’ayant pas besoin de conserver son contenu dans une colonne distincte de la colonne de résultat, nous pouvons directement la modifier.



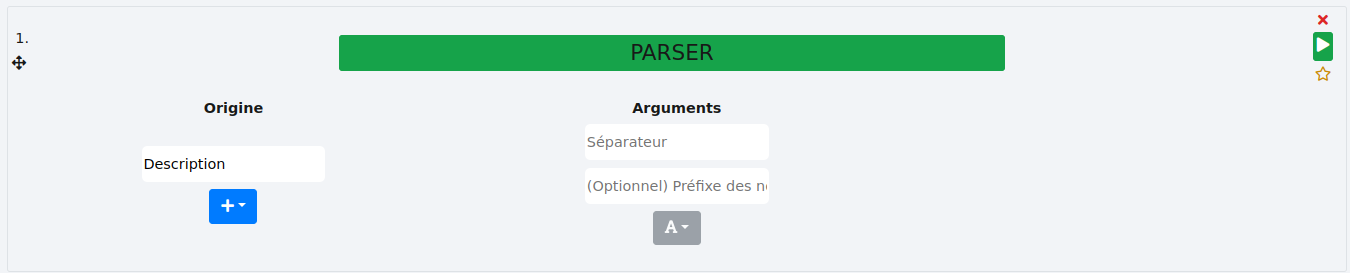
# PARSER
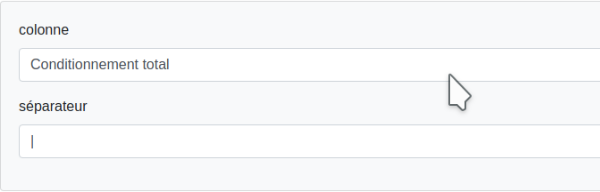
Cette fonction crée des colonnes et affecte leurs contenus à partir d’une colonne.
- Exemple :
Dans le cadre d’un commerce électronique, nous avons une colonne "Description" regroupant plusieurs attributs produits.
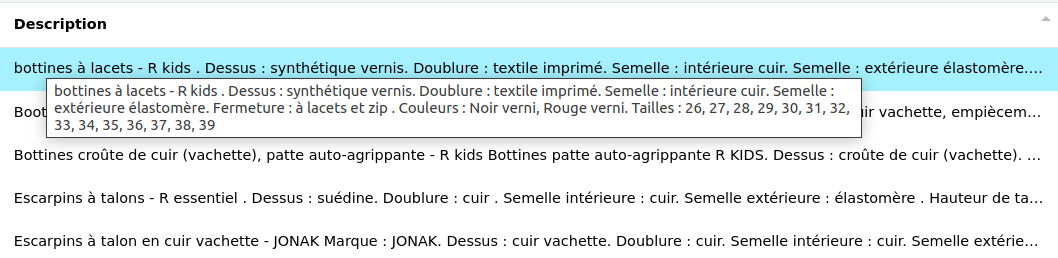
Chaque attribut est présenté de cette façon : "nom de l’attribut" : "texte descriptif". Tous les attributs sont séparés par un ".".
Nous précisions la colonne d’origine, ici "Description".
Puis nous précisons le séparateur, ici le point ".".
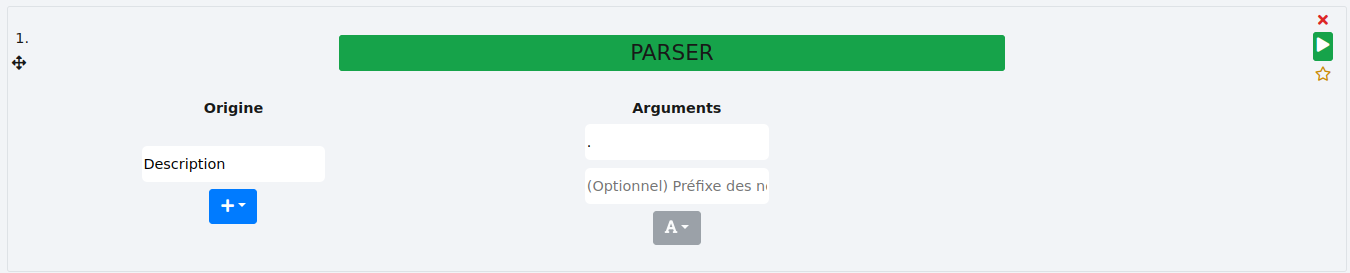
Ce qui nous donne ceci :

Chaque attribut est désormais une colonne et leurs descriptions sont dans leurs cellules respectives.
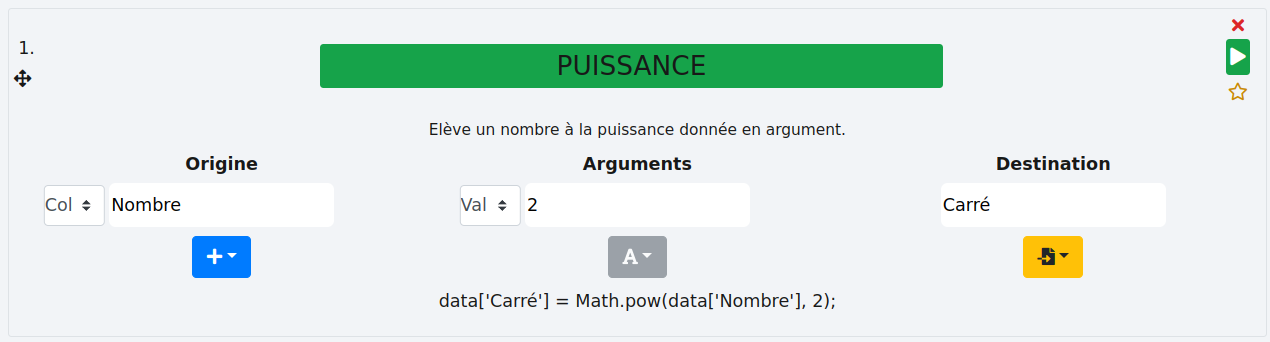
# PUISSANCE
Cette fonction passe les nombres d’une ou plusieurs colonne à la puissance définie qui peut être une valeur fixe ("Val") ou dynamique dans une colonne spécifique (option "Col").
Valeur :
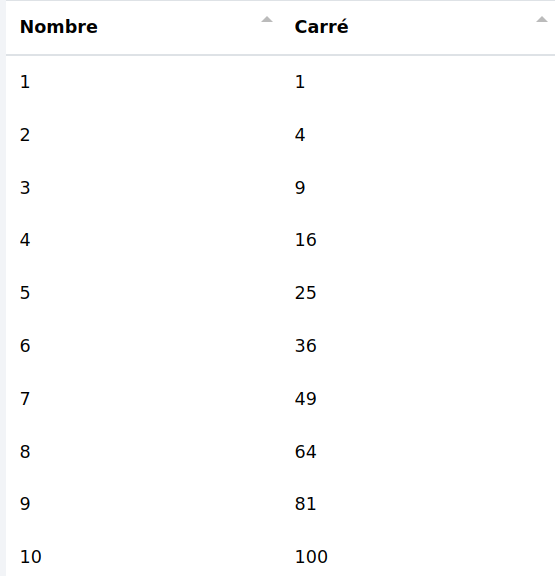
Par défaut, la puissance est de "2". Dans cet exemple, nous voulons le carré des cellules de la colonne "Nombre" qui sera stocké dans la colonne "Carré".
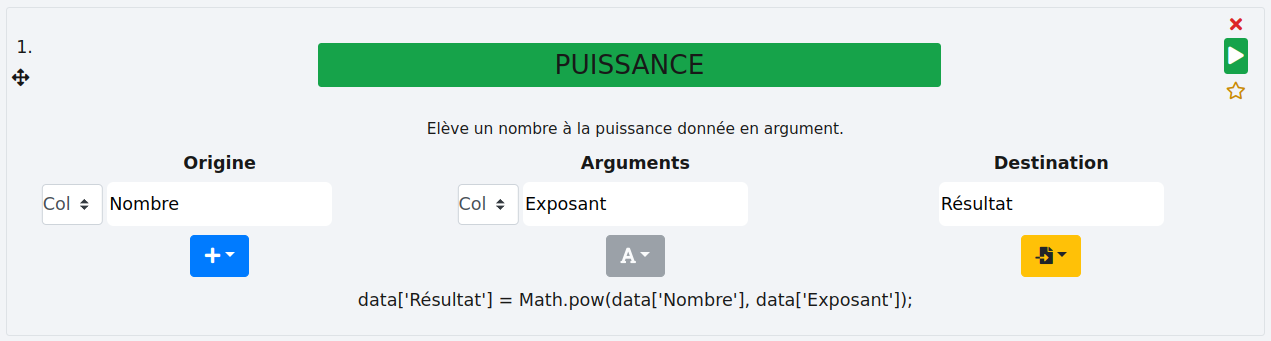
Colonne :
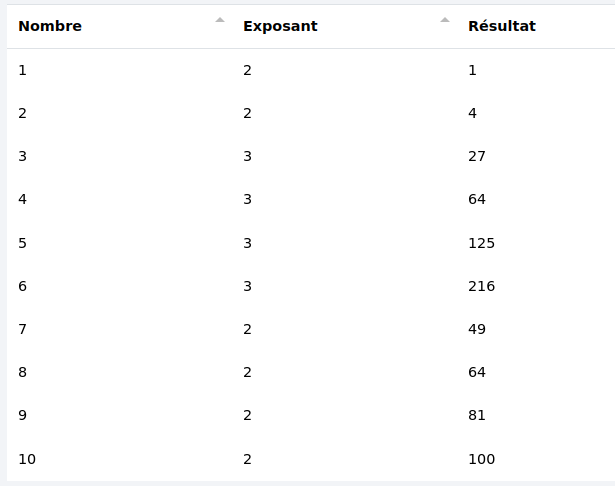
Dans cet exemple, nous avons une colonne "Nombre" et leurs exposants respectifs dans la colonne "Exposant". Le résultat sera stocké dans la colonne "Résultat".

# SPLIT
À partir de la colonne d’origine comportant un intervalle comme par exemple “1999-2024”, cette fonction crée une nouvelle ligne par année. Exemple avec cette ligne en données d’entrée : Des exemples seront plus parlants. En voici deux.
Tailles :
Nous avons un fichier de chaussures avec une colonne regroupant leurs tailles disponibles. Nous souhaitons créer une ligne par chaussure et par taille.
Nous sélectionnons la colonne "Tailles". Les pointures sont séparées par une virgule.
Le réslutat est un fichier où chaque ligne correspond à une chaussure associée à une taille. Le produit CH001 existe donc de la taille 26 à 39.

Années :
Cette fois, nous avons un fichier regroupant des motos. Chacune d’entre elles a une déclinaison courant sur plusieurs années données par un intervalle dans la colonne "Années".

Comme précédemment, l’objectif est d’obtenir pour chaque ligne un produit associé à une année et non un intervalle comme au départ. Nous allons donc travailler à partir de la colonne "Années". Le séparateur est ici un trait d’union "-" et pour être sûr que l’incrément se fasse bien d’une année à l’autre, option "intervalle" est mise à 1.

# SUBSTITUE
Cette fonction remplace une expression par une autre dans la colonne d’origine. Les deux arguments sont nécessaires.
# TRIM
Cette fonction supprime les espaces en début et en fin de cellule. Il est possible de spécifier plusieurs colonnes.
- Exemple :
Prenons l’exemple des colonnes "NOM" et "PRENOM" dont les contenus ont des espaces avant et après.


On sélectionne les deux colonnes dans "Origine".
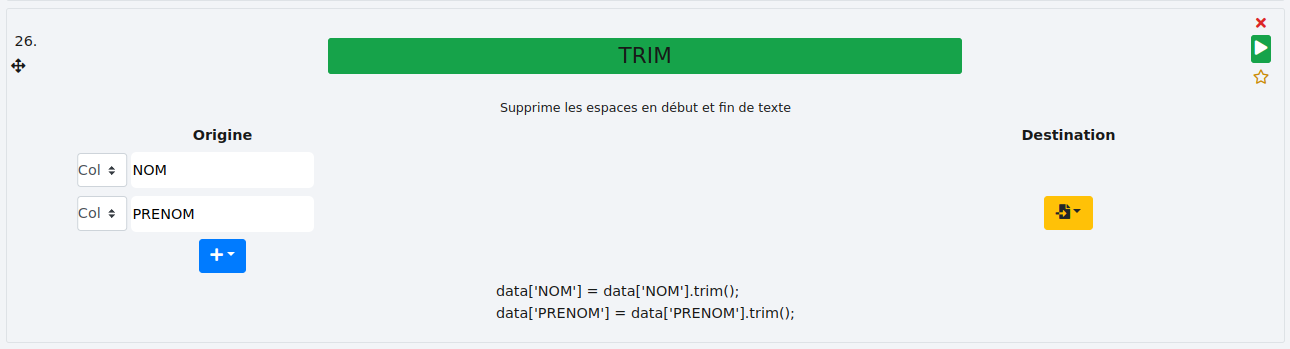
Les espaces sont alors supprimés.


# Fusionner lignes
Permet de fusionner les lignes du tableau sur une colonne clé (Colonne id). Dans le cas où plusieurs valeurs seraient regroupées dans une même cellule, le séparateur sera inséré entre elles.

Ici, nous fusionnons les lignes sur la colonne “Nom”. Le “|” est notre séparateur.
Avant :
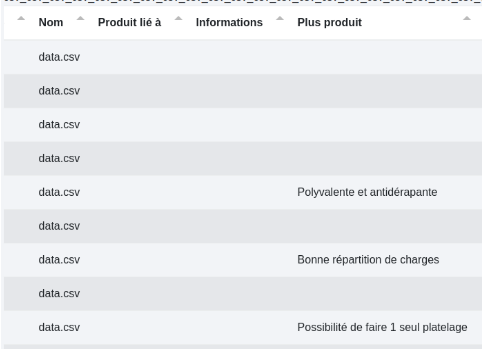
Après :

# Générer document
Cette étape permet de créer des templates html utilisables tels quels ou convertibles en documents pdf.
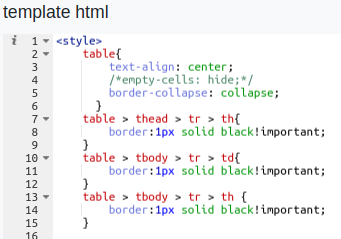
# Création d’un template
La création du template se fait de la même façon qu’une page web. Inutile d’ajouter les balises "DOCTYPE" et "html". Les balises "style" et "script" permettent respectivement de personnaliser la page et d’ajouter du code JavaScript.

# Handelbarjs
L’étape utilise la bibliothèque handlebarjs. Voici quelques-unes de ses possibilités.
# Récupération de données
handlebarjs permet de récupérer dynamiquement les données à afficher dans le template.
Exemple avec ces données d’entrée

et le détail de la colonne "response"

, le code suivant

permet d’obtenir ceci :

# Boucles
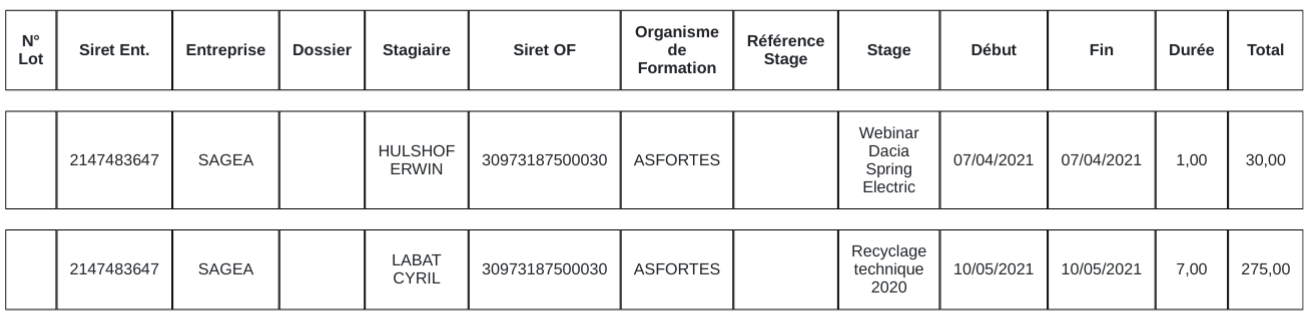
On peut aussi boucler sur une colonne comme ici avec "data" :
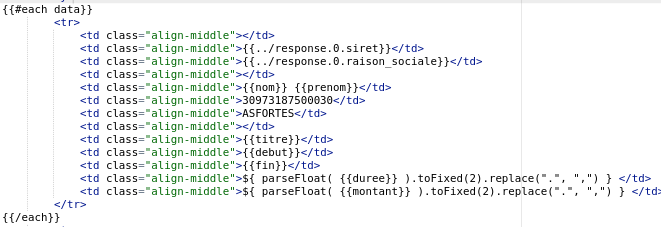
Et nous obtenons alors une ligne par stagiaire :
# Opérations
Les classiques opérations sur nombres sont possibles mais les données du csv sont toutes de type string et nécessitent d’être converties au bon format comme ici :

Pour aller plus loin : Les littéraux de gabarits.
# Un peu de CSS
Par défaut, la page est en format portrait mais il est possible de la passer en mode paysage en ajoutant ce code CSS :

Créer une nouvelle page à chaque tour de boucle peut se faire avec "break-before: page ou break-after: page
# Visionneuse
Cliquer sur le bouton "Test" permet de voir immédiatement le résultat du template et de naviguer entre les différentes pages le cas échéant.
Première page en mode portrait :

Seconde page en mode paysage :

# Paramétrage
# Template ou template multi pages?

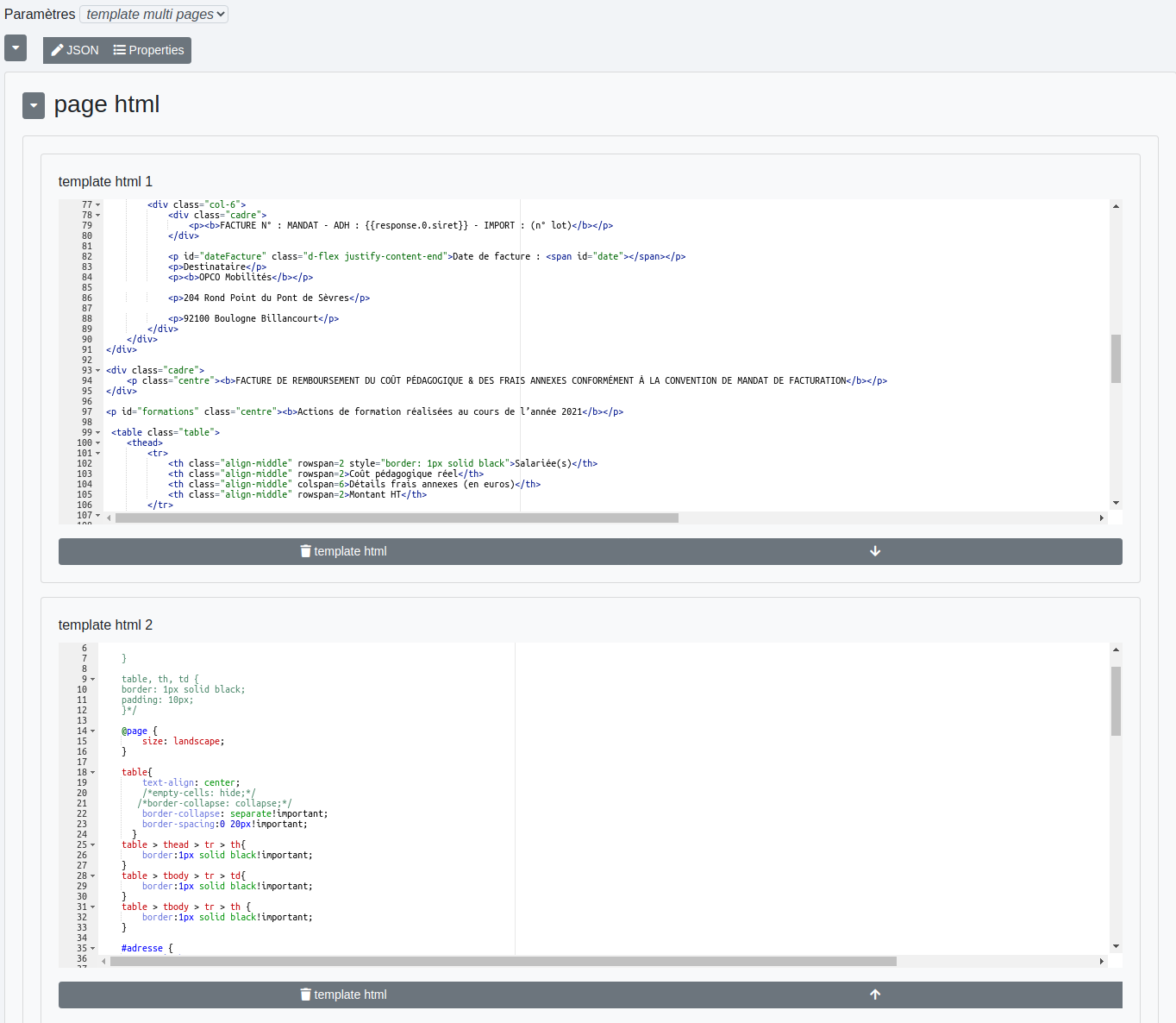
- template : permet de créer un template HTML éventuellement convertible en PDF. Il est possible de le découper en plusieurs pages pour créer ce document. Toutes les pages auront alors le même format (portrait ou paysage);
- template multi pages : Comme précédemment à ceci près que toutes les pages peuvent ne pas avoir le même format. Cela nécessite de créer un template par page. De plus, le type de sortie ne peut être que PDF.
# Les autres paramètres
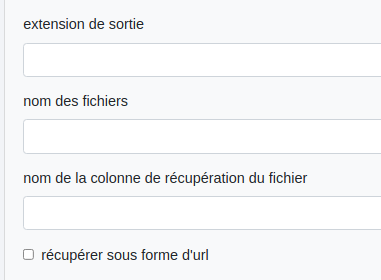
- extension de sortie : html ou pdf;
- nom des fichiers : définition dynamique des noms de fichiers avec cette écriture : ${data.nomColonne};
Exemple de nommage dynamique avec ces données :


- nom de la colonne de récupération du fichier : nom de la colonne du csv de sortie où seront stockés les fichiers. Dans le cas où l’extension est "pdf", la récupération des fichiers se fera uniquement sous forme d’url dans cette colonne. Si aucune colonne n’est précisée, les fichiers seront directement retournés.
- récupérer sous forme d’url : à cocher si on souhaite récupérer les fichiers sous forme d’url dans une colonne spécifique du csv (précisée plus haut). Ces url ne sont utilisables que dans le cadre d’un scénario ou d’un traitement.
# Hit Parade
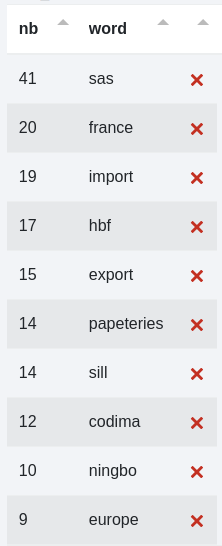
Sa fonction est double : fournir des statistiques et permettre la création rapide d’une liste.
Je veux connaître par exemple, le nombre de produits de chaque fournisseur présents dans mon catalogue. Aucun nom pertinent n’a moins de trois lettres.

Ce qui me donne :

Dans le cas où la case "Découper en mots" est cochée, tous les mots de la colonne sont utilisés pour calculer les occurrences.
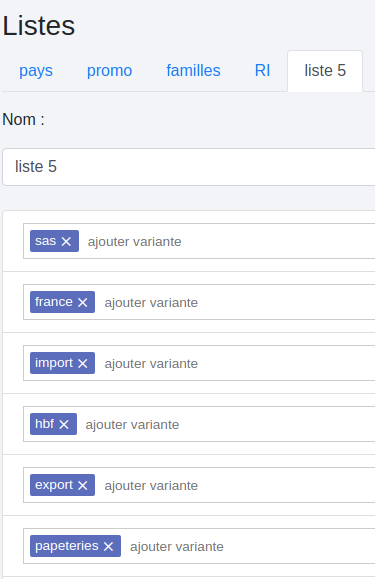
Pour créer une liste à partir de ce résultat, il suffit d’éliminer les termes non désirés puis de cliquer sur le bouton  . La nouvelle liste sera visible dans l’onglet listes.
. La nouvelle liste sera visible dans l’onglet listes.
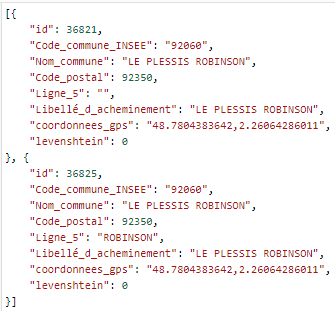
# INSEE
Cette étape interroge une base de données issues de la base officielle des codes postaux.
# Les paramètres
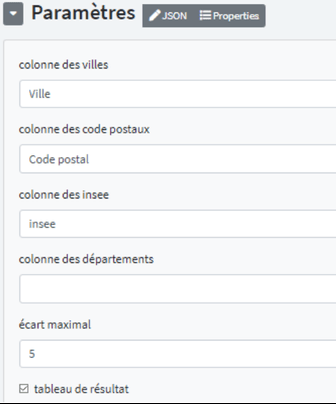
- Colonne des villes : colonne où le sercice prendra les noms de villes;
- Colonne des codes postaux : colonne où seront pris les codes postaux;
- Colonne des codes INSEE : colonne des codes INSEE. Si les données sont présentes, elles seront utilisées par le service. Dans le cas contraire, elles y seront ajoutées;
- Colonne des départements : colonne des départements au fonctionnement identique à la colonne des codes INSEE;
- Ecart maximal : maximum de caractères différents entre l'expression recherchée issue du csv et les valeurs cibles de la base de données;
- tableau de résultats : permet d'obtenir la liste des résultats sous forme de JSON dans le cas où plusieurs villes ont le même code postal.
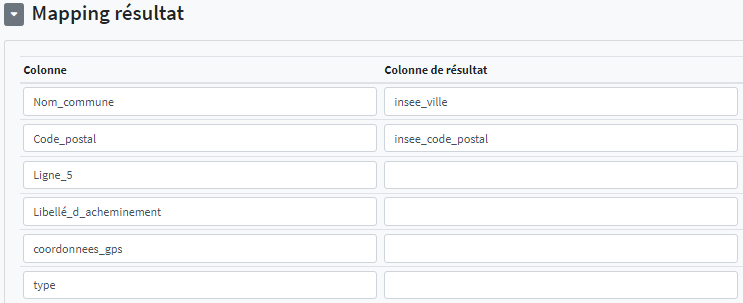
# Mapping résultat
Cette fonctionnalité permet de préciser les colonnes où seront ajoutées les résultats souhaités. Dans l'exemple suivant, les résultats "nom_commune" et "Code_postal" issus du service sont conservés, dont deux dans des colonnes renommées. Les autres comme "Ligne_5" et "coordonnées_gps" par exemple, ne sont pas conservées (voir la base officielle des codes postaux pour plus de détails).
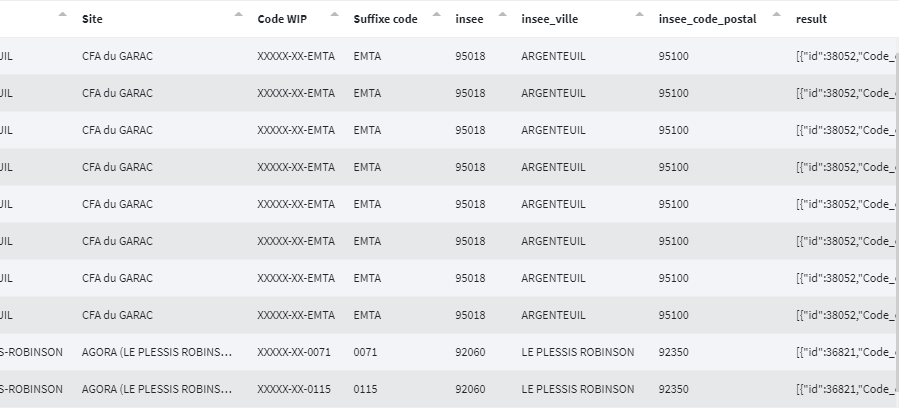
Exemple de résultat :
# Mapping colonnes
Permet d’effectuer le mapping entre le fichier d’origine et le fichier cible. La colonne de gauche présente les noms des colonnes du fichier d’origine; celle de droite permet de les réécrire au besoin. Les flèches de droite permettent de réorganiser les colonnes et la poubelle de les supprimer. Attention à ne pas en avoir besoin pour des traitements ultérieurs.
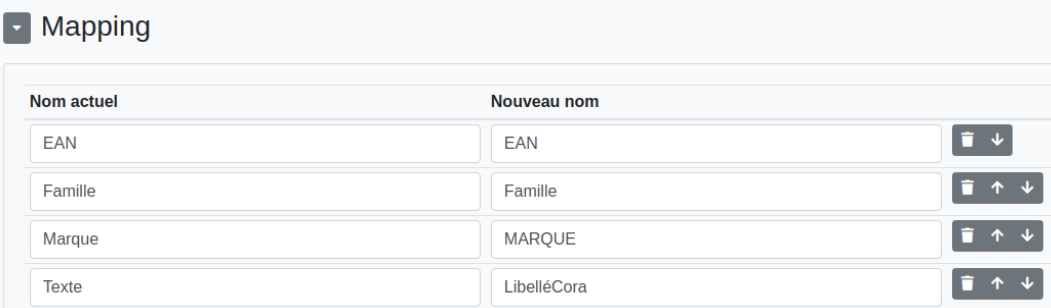
La barre du bas permet d’ajouter des colonnes, d’enlever la dernière ou éventuellement toutes.

# Mapping colonnes - fichier cible
Elle fonctionne comme l’étape de “Mapping colonnes” à ceci près qu’elle part des colonnes du fichier cible et non du fichier d’origine.
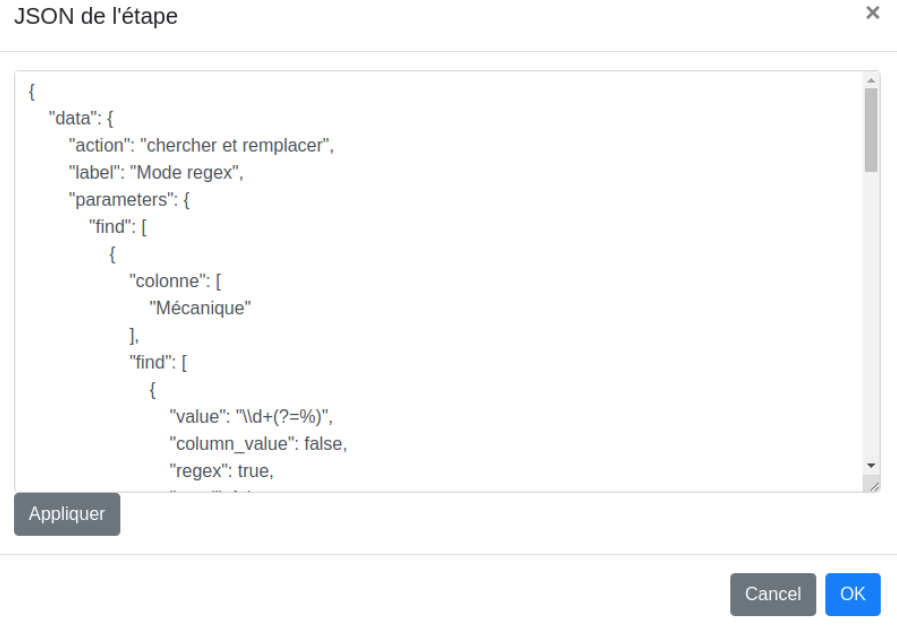
# Mode regex
Cette étape ressemble au "chercher et classer" mais offre une plus grande souplesse d’utilisation notamment dans l’usage des regex. De ce fait, elle est aussi plus complexe à maîtriser. Comme dans "chercher et classer", on peut effectuer plusieurs recherches les unes à la suite des autres.
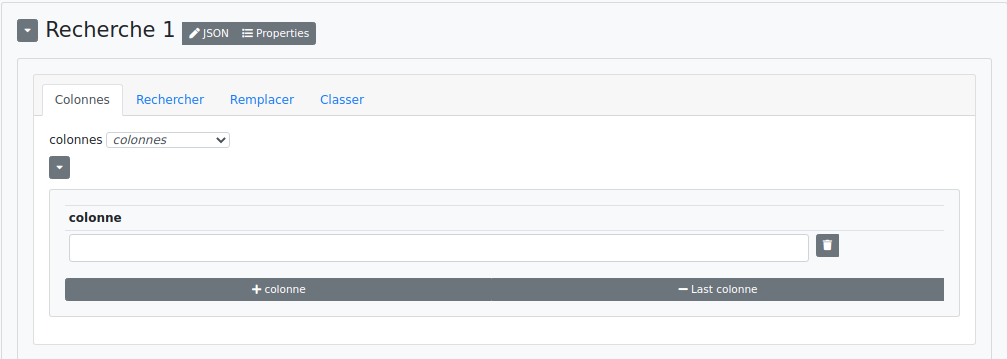
Chaque recherche se compose de quatre onglets :
Colonnes :

- Colonnes : sélectionné par défaut. On entre alors le nom de la colonne où chercher.
- Colonnes (regex) : si sélectionné, on entre ici un regex permettant de cibler toutes les colonnes lui correspondant.
Rechercher :
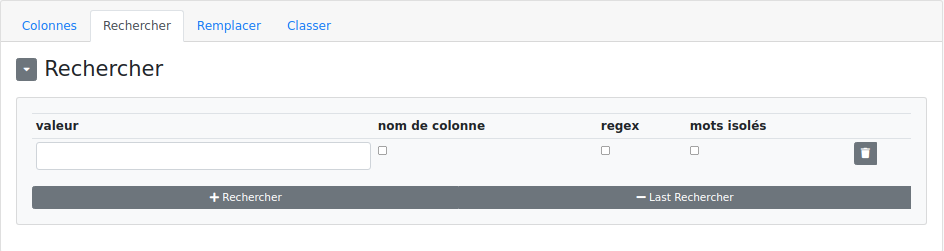
- Valeur : ce qu’on recherche.
- Nom de colonne : coché si on entre dans le champ "Valeur", le nom de la colonne contenant les valeurs recherchées dans la colonne cible.
- Regex : à cocher si l’expression entrée dans le champ "valeur" est un regex.
- Mots isolés : dans le cas où plusieurs valeurs sont retournées, seule la première est conservée.
Remplacer : Permet de remplacer tout ou partie du résultat trouvé par d’autres valeurs.
- Groupe : le groupe du regex qu’on souhaite remplacer. Si vide, l’ensemble du résultat sera remplacé.
- Remplacé par : valeur de remplacement.
Ici, nous effaçons le résultat de la recherche :
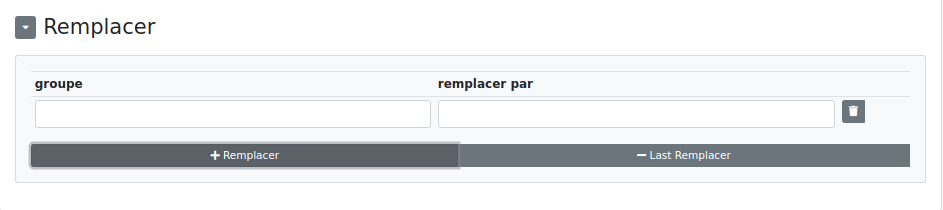
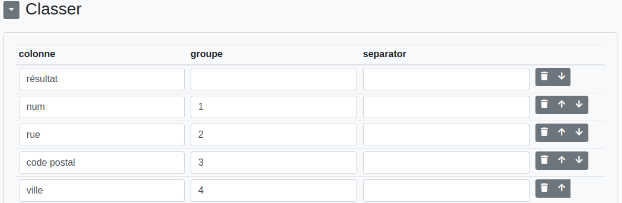
Classer : Permet de classer tout ou partie des éléments trouvés lors de la recherche. À noter que, contrairement à l’étape "chercher et classer", on peut classer le résultat de la recherche dans la colonne de recherche.
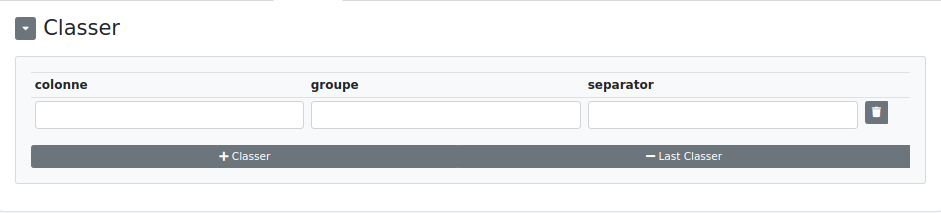
- Colonne : la colonne où sera classé le groupe (ou l’ensemble du résultat).
- Groupe : le groupe du regex qu’on souhaite classer. Si vide, l’ensemble du résultat sera classé dans la colonne.
- Separator : dans le cas où plusieurs valeurs sont trouvées et où "separator" est vide, alors seule la dernière valeur sera retournée. Si nous avons par exemple un "|" ou un "-" en séparateur, alors toutes les valeurs seront retournées, séparées par le caractère choisi.
Exemple 1 :
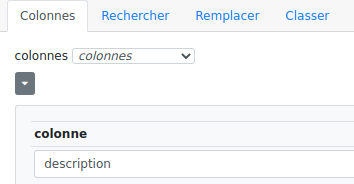
Données initiales :

Nous cherchons dans la colonne "description"…
…tous les nombres via un regex.
Nous classons les nombres trouvés dans la colonne "nombre" en les séparant par un "-".

Résultat :

Si "separator" avait été vide, seul le nombre "44442" serait apparu.
Exemple 2 :
Nous cherchons le nombre 42 dans la colonne "description" que nous stockons dans la colonne "nombre" comme précédemment.

Résultat :

En cochant "mots isolés", seule la première occurence est conservée.
Il est possible de le combiner avec "nom de colonne" qui ici, recherche la valeur qui est dans la colonne "recherche".

Résultat :

Exemple 3 - les regex et les groupes :
Voilà un regex pour avoir l'adresse. Les parenthèses permettent de créer des groupes.
Avec cette recherche et ce classement…

… on obtient ceci :

Il est possible de concaténer des groupes :
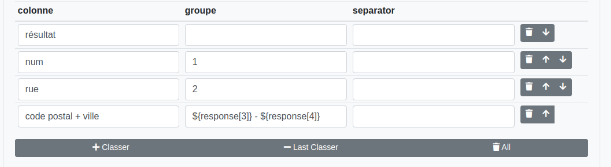

Response étant le résultat du regex, response[0] correspond à l’ensemble du résultat, response[1] au premier groupe, etc.
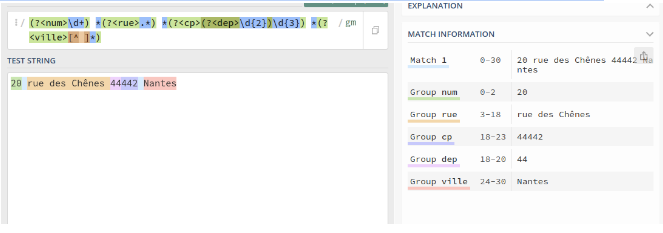
On peut utiliser des noms pour les groupes en écrivant (?<nom_du_groupe>regex). On peut avoir des groupes dans des groupes comme ici avec le département.
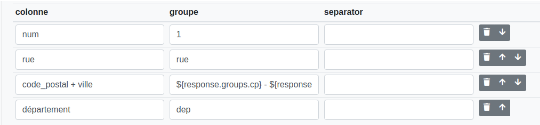

On peut simplement utiliser le nom de la colonne ou response.group.nom_group pour les concaténation. Les numéros des groupes sont toujours disponibles.
Enfin, il est possible d’utiliser les groupes dans les remplacements.
On remplace ici l’adresse par le code postal.


# Normalisation
Elle permet diverses opérations sur colonne comme le passage en minuscules, majuscules, nom propre ou encore de mettre la première lettre d’une phrase en majuscule sur la colonne cible. Mais il est également possible de rechercher des valeurs spécifiques et de les remplacer comme dans l’exemple ci-dessous :

Exemple :

Les actions peuvent se combiner. Il est possible de mettre en majuscules et de remplacer par exemple :

# Partage de document
Cette étape permet de stocker des documents précédemment créés par notre générateur sur notre espace de stockage.
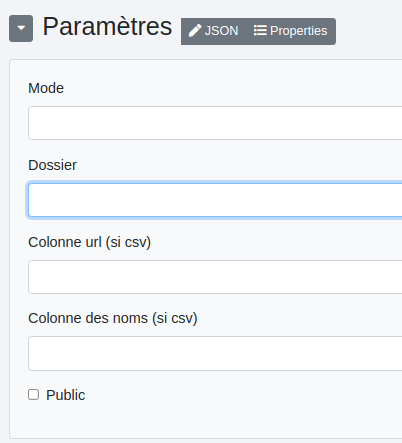
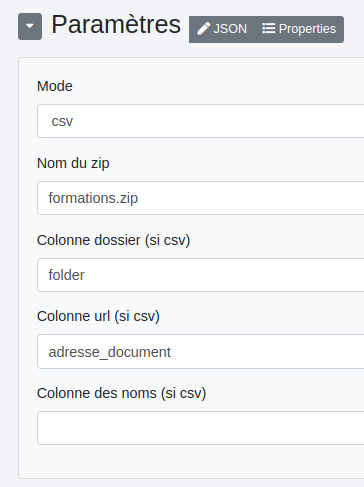
Mode : deux options :
- fichiers : permet de copier un ou des fichiers dans l’espace de stockage, peu importe son format.
- CSV : si un fichier CSV est en entrée.
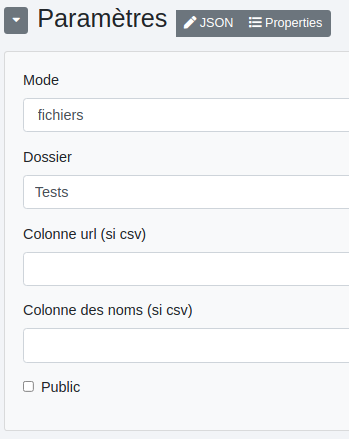
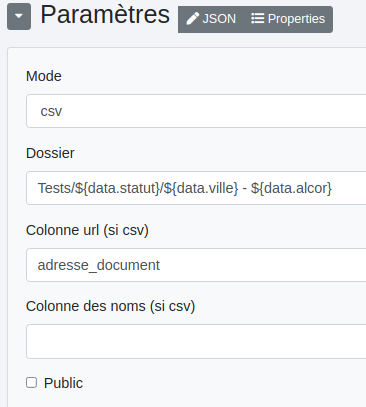
Dossier : noms des dossiers où seront stockés les fichiers. Ces noms peuvent être dynamiques en utilisant la notation ${data.nom_de_colonne} et il est possible de créer des chemins complets comme dans l’exemple ci-dessus. Colonne url (si csv) : la colonne où sont stockées les url des fichiers à copier dans l’espace de stockage. Colonne des noms (si csv) : la colonne des noms de fichiers s’ils sont prédéterminés dans le csv (non dynamiques). Public : Rend le fichier public.
# Mode fichiers
Nous avons ces données initiales :
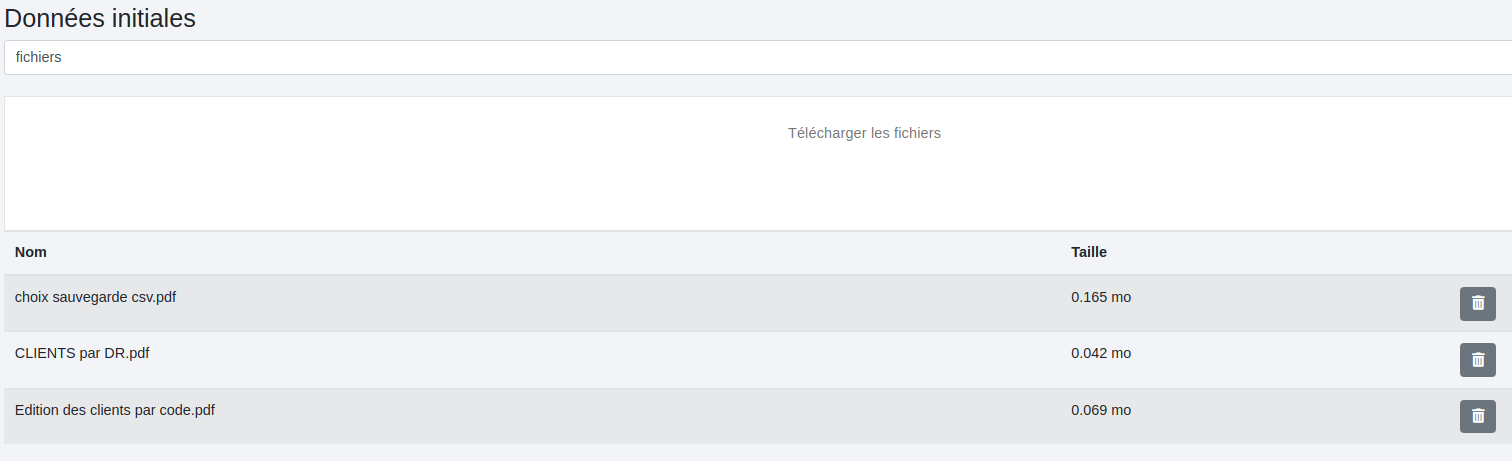
Les paramètres :
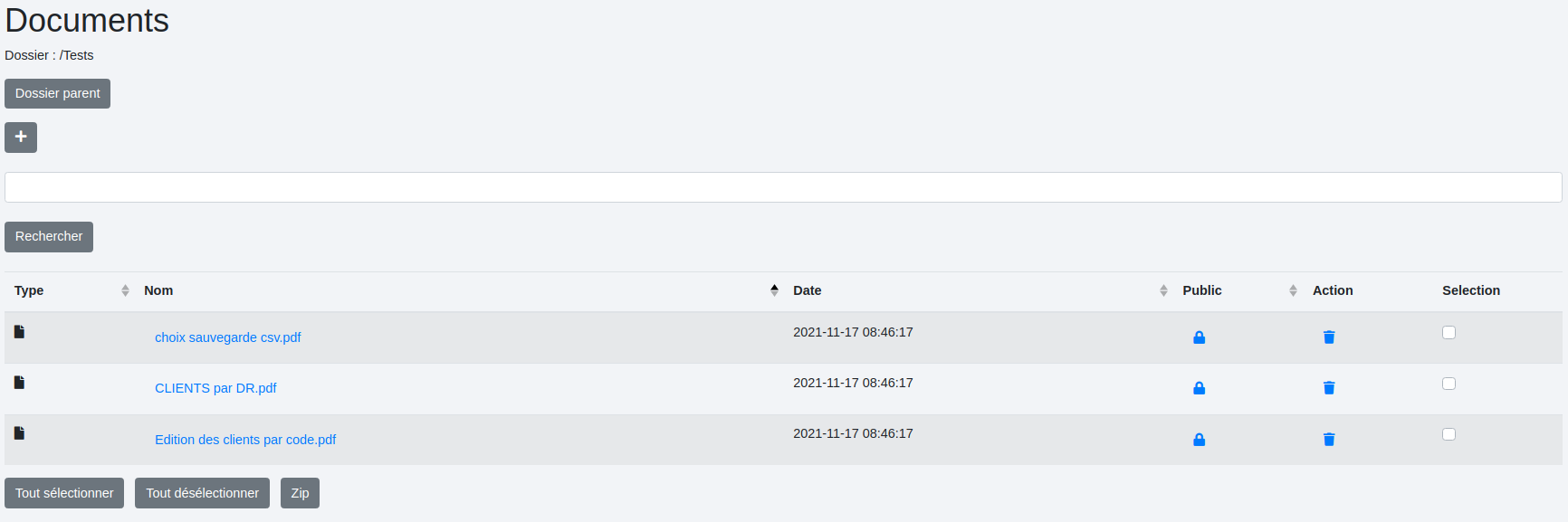
Et voici le stockage dans l’espace "Documents" :
# Mode CSV
Nous avons ces données initiales :
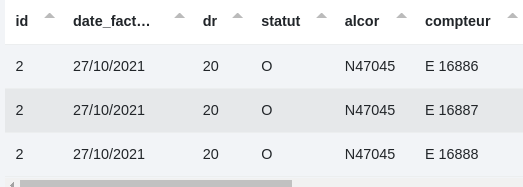
Avec ce paramétrage :
Nous obtenons cette arborescence :
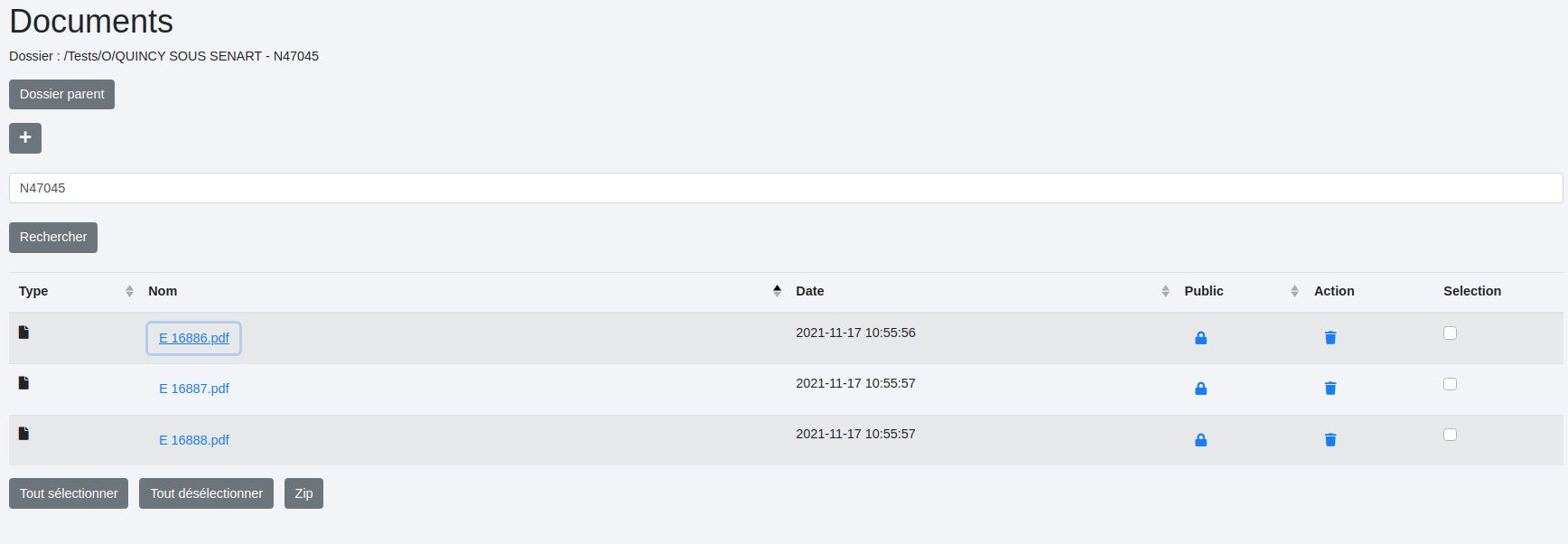
On a bien le chemin voulu avec "Tests" suivi du statut "O", de la ville "QUINCY SOUS SENART" et du numéro ALCOR "N47045".
# Projet
Cette étape permet d’appeler un projet pour l’ajouter partiellement ou totalement au scénario au rang de cette étape.
Sélection du projet :

Sélection de la partie du projet :

Les noms des parties correspondent aux tags déclarés dans le scénario d’origine (voir la section tags pour de plus amples explications).
# Référentiel
Cette étape est un arbre de décision permettant de réaliser des actions sous conditions.
Par exemple, nous souhaitons réaliser cet enchaînement à partir de ces données initiales :


Nous devons effectuer un premier classement à partir de la catégorie "chaussette" ou "chaussure".

Nous ajoutons un premier niveau dans les paramètres. La condition va concerner la colonne "categorie".

Nous cliquons sur le bouton "Ajouter" qui ajoute notre première condition de niveau 1 dans le référentiel.

Le champ conditionnel apparaît alors puis nous précisons la condition : "si la catégorie est "chaussette" alors…"

Nous avons notre premier niveau conditionnel.
Nous ajoutons un second niveau conditionnel qui va concerner la colonne "prix" cette fois. Mais nous avons aussi une action concernant une nouvelle colonne "classe" : 
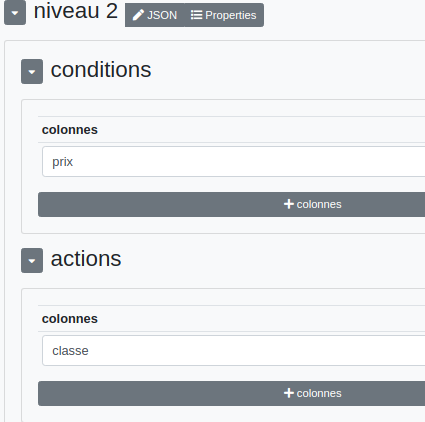
Dans le référentiel, il faut ensuite cliquer sur le bouton  pour faire apparaître le second niveau.
pour faire apparaître le second niveau.

Lecture : si la catégorie est "chaussette" et si le "prix" est égal à 20 alors la colonne "classe" prend la valeur "normal".
Nous continuons ainsi pour le seconde condition sur le prix : 
Dans le référentiel, nous faisons apparaître une nouvelle condition de second niveau en cliquant sur le bouton sous le terme "categorie". Les conditions d’un même niveau apparaissent dans le même cadre.

Nous avons alors réalisé la première partie :

Place à la seconde! Un clic sur le bouton  fait apparaître une nouvelle condition de niveau 1. Elle concerne toujours la colonne "categorie" mais nous y entrons la valeur "chaussure" cette fois.
fait apparaître une nouvelle condition de niveau 1. Elle concerne toujours la colonne "categorie" mais nous y entrons la valeur "chaussure" cette fois.
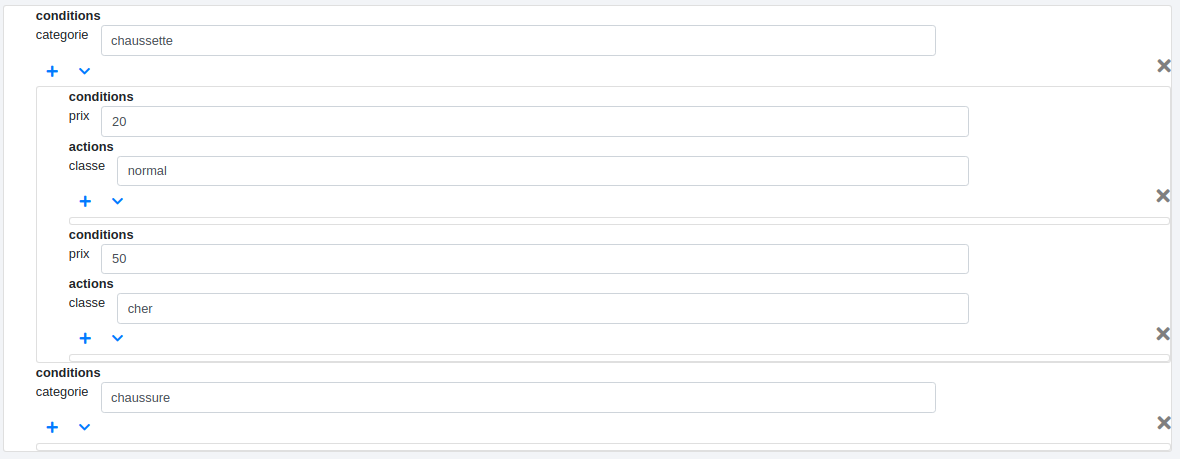
La définition des conditions de niveau 1 et 2 dans les paramètres permet de ne pas avoir à les réécrire à chaque fois. Chaque nouvelle condition de niveau 1 portera sur la colonne "categorie", de même que chaque nouvelle condition de niveau 2 concernera la colonne "prix" avec une action sur la colonne "classe". Il ne reste plus ensuite qu’à préciser leurs valeurs respectives.
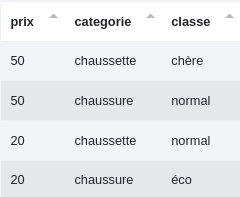
Voici l’arbre de décision terminé :

Que nous pouvons comparer à notre objectif :
Et voici le résultat à partir des données initiales :
# Script personnalisé
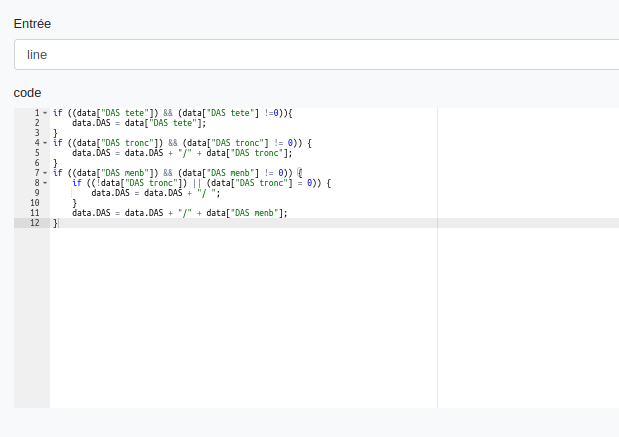
Cette étape est un éditeur de code JavaScript (Node.js) venant compléter les autres étapes. L’entrée par défaut est "line". Ce qui sous entend que chaque ligne du tableau est un objet appelé "data" dans le code. On peut dès lors appeler le contenu d’une colonne de cette façon : data.nomColonne ou data["nom colonne"].
Si l’entrée est file, c’est le fichier complet que reçoit "data". Enfin, dans le cas d’un ensemble de fichiers avec files sélectionné, "data" comprend le groupe de fichiers. Il est alors possible d’en sélectionner un en utilisant la notation pointée : data.fichierVoulu.
# Siren
Cette étape interroge la base de données siren de data.gouv.fr et utilise cette API.
Elle offre trois types de recherche : par siren, siret ou en recherche libre.

# Recherche par Siren
1 - La première utilisation consiste à déclarer la colonne contenant les numéros SIREN à rechercher.
Données d’entrée :

Les paramètres :

Le service renvoie la réponse au format json dans une nouvelle colonne avec une colonne "error" en cas de problème.

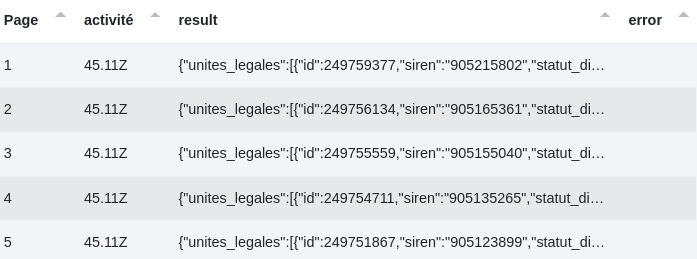
2 - Dans le cas où le fichier d’entrée ne dispose pas d’une colonne regroupant les numéros siren, il reste possible d’effectuer une recherche en prenant pour base les couples "clés:valeurs" du fichier json type retourné par l’API gouvernementale.

Attention! Seules les clés possédant une valeur sont accessibles. "etablissement_siege" et "etablissements" ne peuvent donner des résultats car contenant de multiples valeurs.
On peut alors ajouter des filtres portant le nom du ou des champs voulus. Les valeurs se trouvant dans une colonne spécifique comme ici :
Données d’entrée :

Paramètres :


Exemple de sortie :
# Recherche par Siret
1 - Comme pour le Siren, la première utilisation consiste à déclarer la colonne contenant les numéros Siret à rechercher.
Données d’entrée :
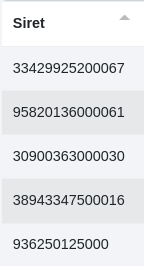
Paramètres :

Comme pour la recherche Siren, le service renvoie une réponse au format json.
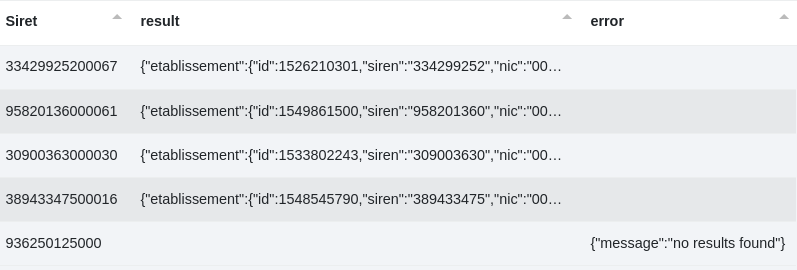
2 - Il est également possible d’effectuer des recherches par filtres de la même manière que pour le mode Siren mais en se basant cette fois sur le json type des établissements.

Une recherche des établissements pharmaceutiques à Nantes donnerait cela :
Données initiales :
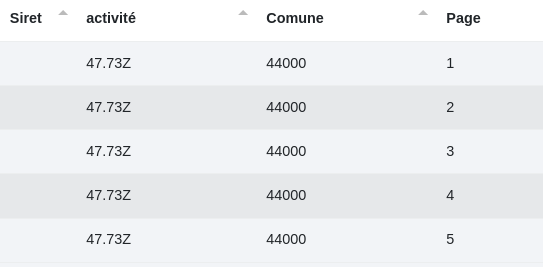
Paramètres :
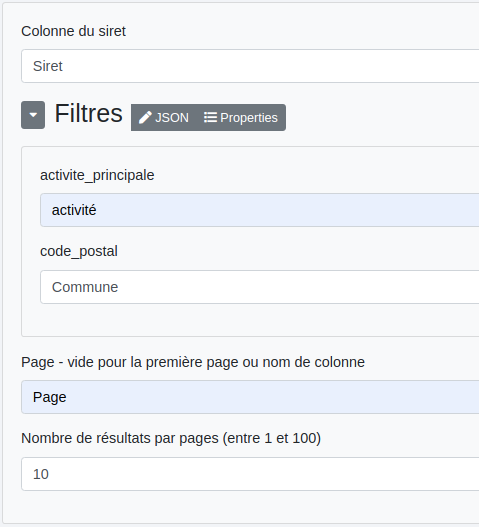
Sortie :
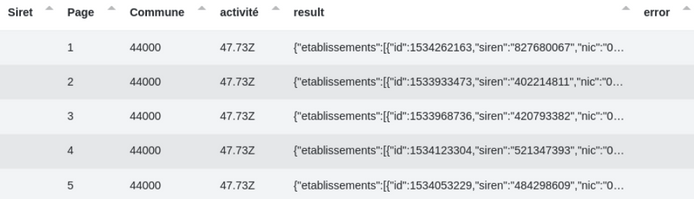
# Recherche libre
L’objectif est ici de rechercher des entreprises par d’autres moyens que les numéros SIREN ou SIRET comme l’adresse, le code postal, la raison sociale, etc. Si je veux rechercher les pharmacies nantaises par exemple, je vais entrer ceci :

Avec ce paramétrage :
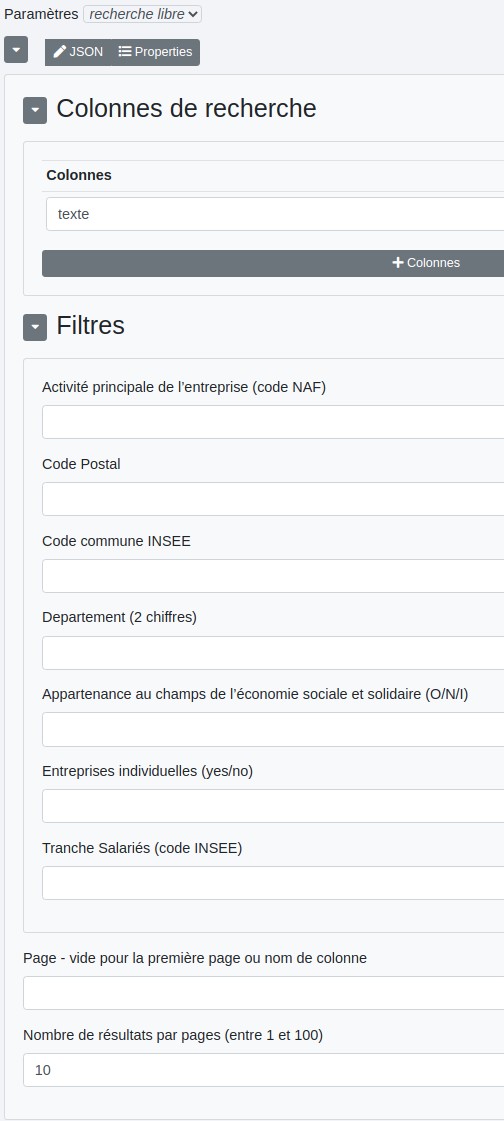
J’obtiens alors ce résultat avec 247 pharmacies réparties sur 25 pages :

Nantes étant une ville relativement importante, je souhaite resserrer ma recherche sur le centre ville. Pour ce faire, je vais utiliser son code postal. Je modifie donc les données d’entrée.

Puis j’ajoute la colonne "code postal" dans le filtre correspondant.

J’obtiens alors 75 pharmacies réparties sur 8 pages.

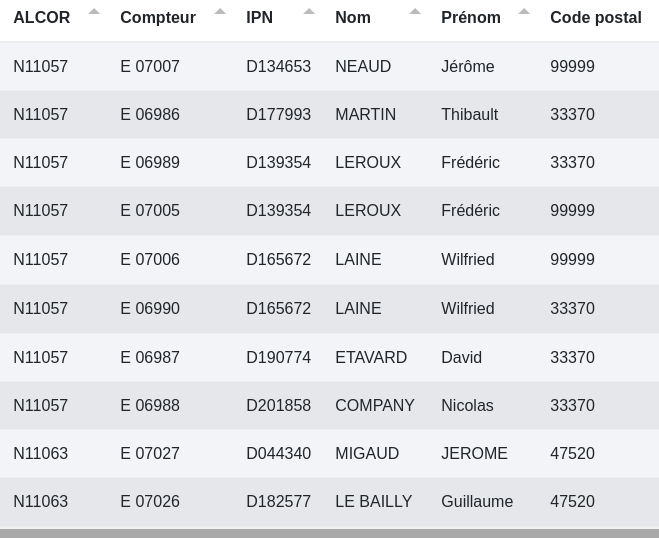
# Sort
Il s’agit ici de trier les lignes sur une ou plusieurs colonnes comme dans un tableur classique de manière croissante ou décroissante.
Exemple :
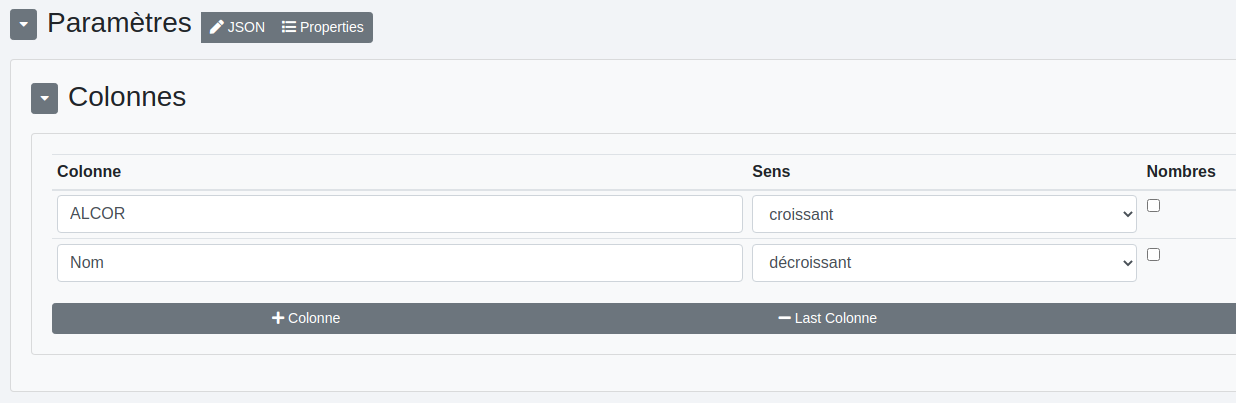
Données d’entrée:
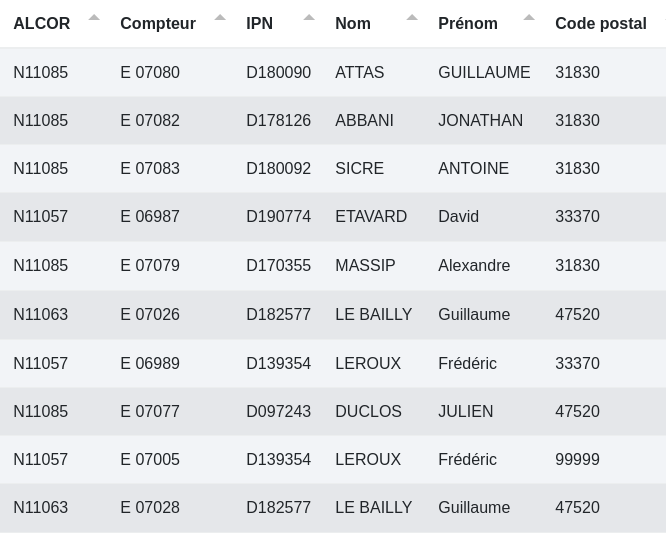
Données de sortie :
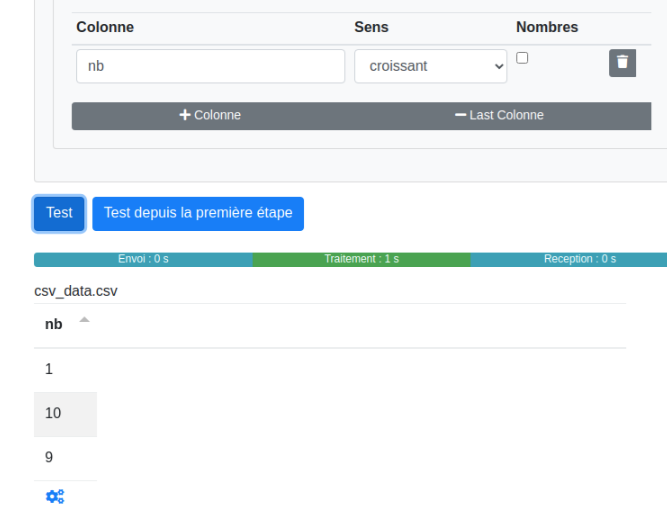
Nombres :
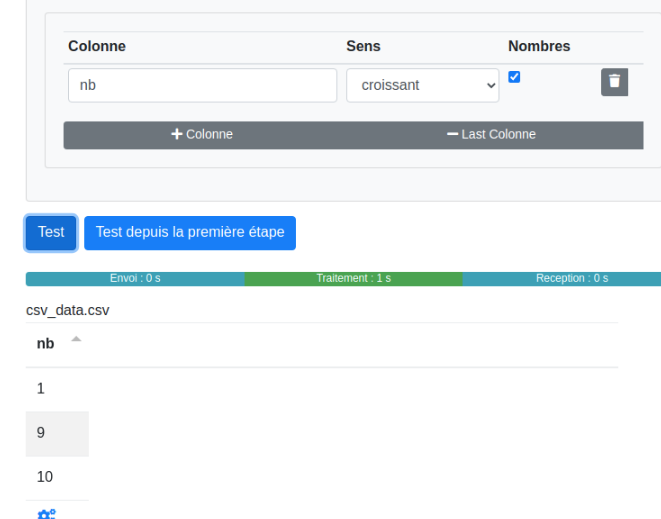
Ne pas oublier de cocher la case "Nombres" si la colonne en contient afin d’éviter ceci :
# Split
Avant :
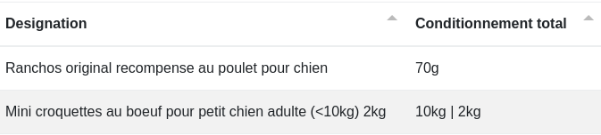
Après :
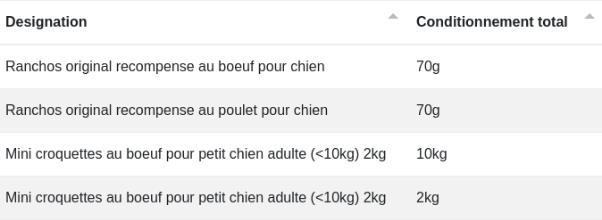
# Split JSON
Données d’entrée :

Paramètres :
Sortie :
Les clés du fichier JSON donnent les colonnes et les valeurs, leurs contenus.

# Supprimer lignes
Cette étape permet de supprimer (ou de conserver si la case est cochée) les lignes correspondant aux conditions définies dans le query builder.

# Textrazor
Basé sur le NLP (Natural Language Processing), Textrazor permet de reconnaître aisément divers types de termes dans un texte comme les noms de villes, lieux, activités, le sujet d’un article, etc.
Le processus se décompose en plusieurs étapes. À partir de ces données initiales :
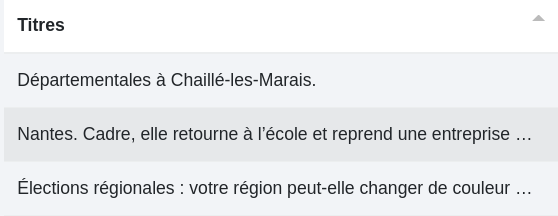
1 - On déclare les éléments à envoyer dans le champ colonne (ici "Titres"). Chaque case cochée donnera naissance à une nouvelle colonne (parfois en anglais).
2 - On test une première fois le service.

Nous avons 6 nouvelles colonnes correspondant aux cases précédemment cochées. Sur ces trois lignes, seules les deux premières comportent une ville que nous souhaitons extraire dans une colonne à part. Dans "Types", nous pouvons remarquer qu’elles ont toutes deux les types "Place" et "PopulatedPlace".
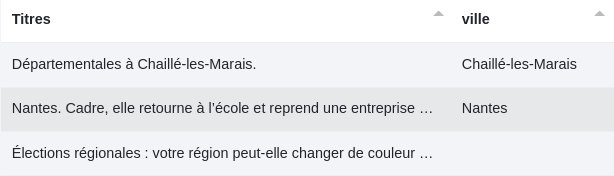
3 - Afin de les isoler facilement, nous déclarons un "type à isoler" ("Place") que nous mettrons dans une nouvelle colonne nommée "ville".

Et cliquons de nouveau sur "test".
Nous obtenons alors nos villes correctement isolées.
# xlsx
Par défaut, l’exportation se fait au format .csv mais il est possible de changer cela pour le .xlsx avec cette étape.

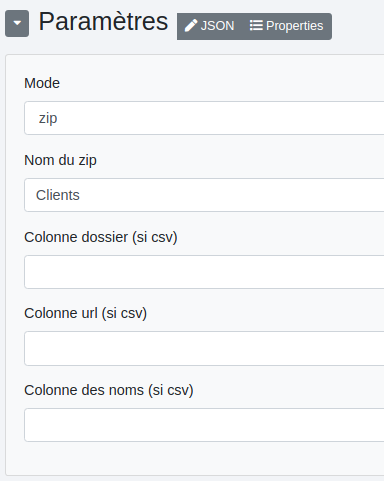
# Zip
Permet de zipper/dézipper des documents.

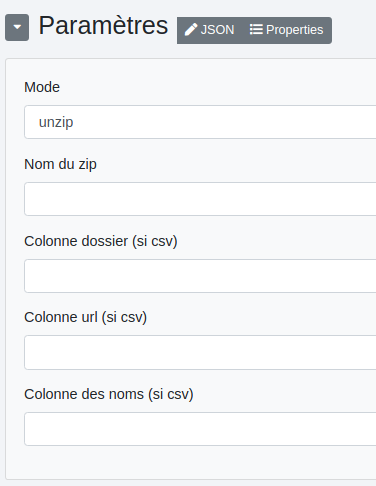
Mode :
- zip : permet de zipper les fichiers d’entrée.
- unzip : permet de dézipper un fichier d’entrée.
- csv : utilise un fichier csv en entrée.
Nom du zip : nom du fichier zip. Colonne dossier (si csv) : colonne des noms de dossiers (les chemins d’accès des fichiers) avec un fichier csv en entrée. Colonne url (si csv): colonne des url des fichiers avec un fichier csv en entrée. Colonne des noms (si csv) : colonne des noms de fichiers avec un fichier csv en entrée.
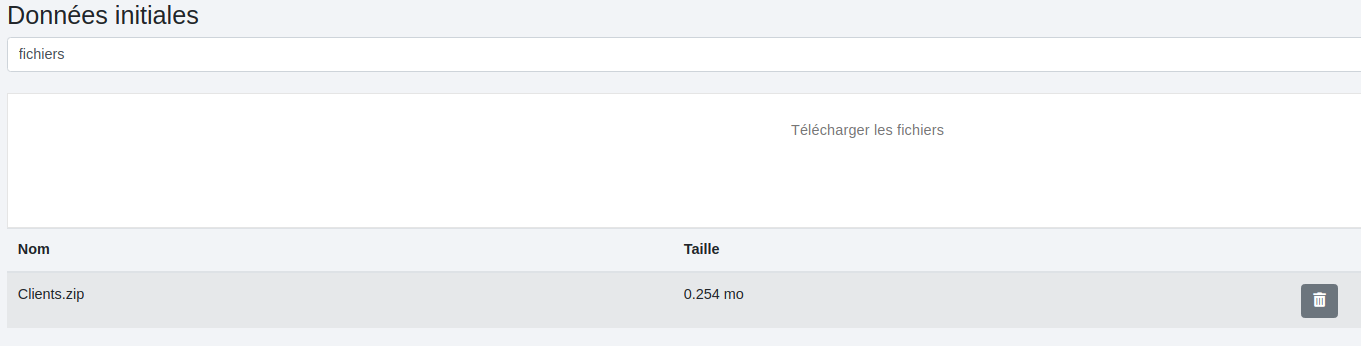
# Mode unzip
Partons de ces données initiales :
Ce paramétrage nous permet de récupérer les fichiers dézippés en sortie :
Sortie :
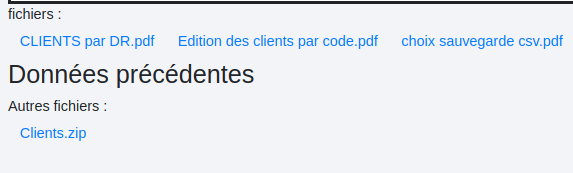
# Mode zip
Nous avons ces trois fichiers en données initiales :
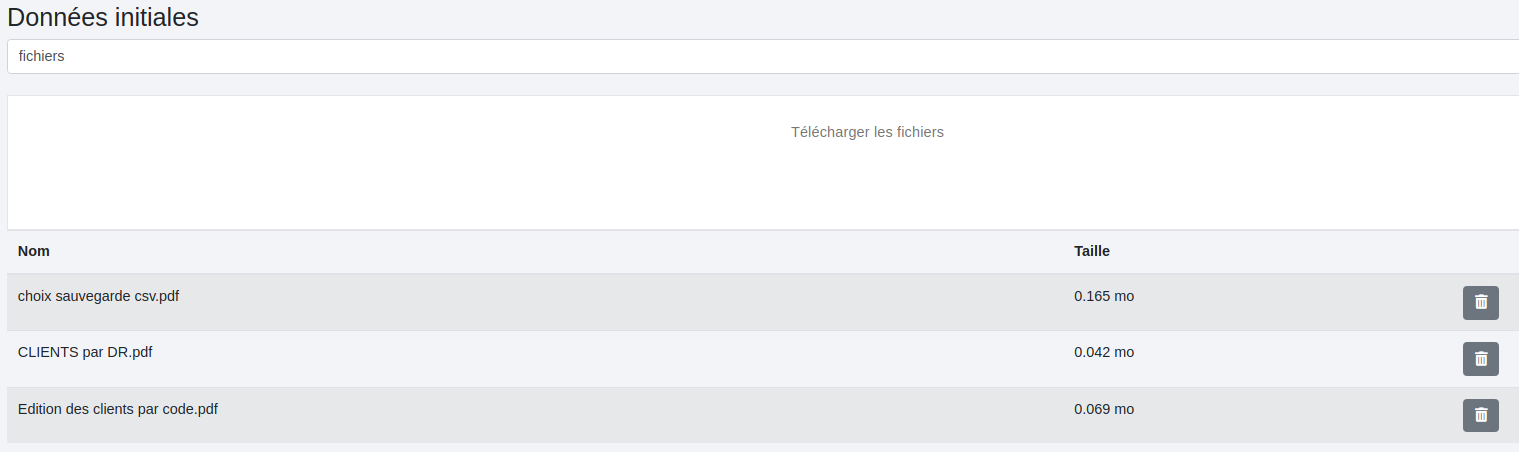
Ce paramétrage nous permet de récupérer les fichiers zippés en sortie :
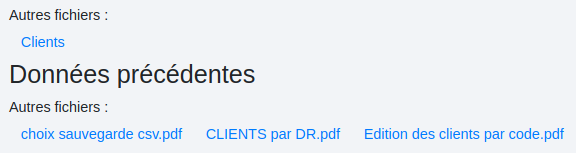
Sortie :
# Mode CSV
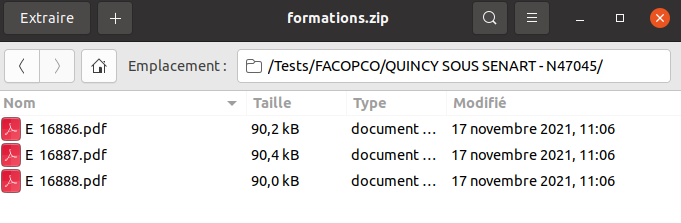
Ce mode permet de créer un fichier zip à partir d’un csv contenant les noms de dossiers, de fichiers ainsi que leurs url de stockage.
Nous partons par exemple de ce fichier csv :

Les paramétres :
L’arborescence du fichier zip de sortie :
# Les regex
Ils peuvent être utilisés dans plusieurs étapes notamment dans “chercher et classer” et “mode regex”. Ce dernier offre plus de souplesse dans leur utilisation.
Quelques liens utiles :
Pour tester vos regex.
Les notions de base.
Voici quelques exemples d’utilisations des expressions régulières (regex) par thèmes.
# Les nombres
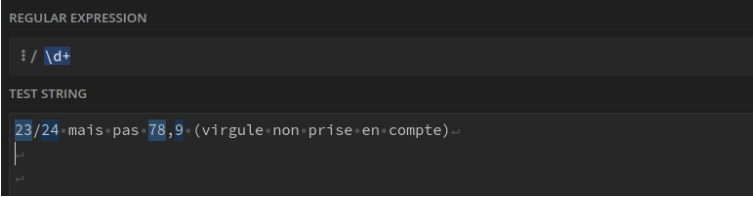
Tous les nombres entiers : \d+
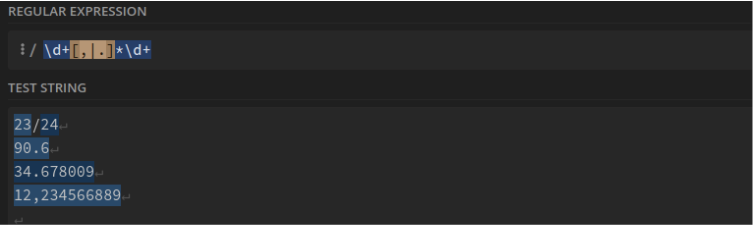
Nombre, décimaux compris, écrits avec une virgule ou un point. Sans limitation au-delà de la virgule : \d+[,|.]*\d+
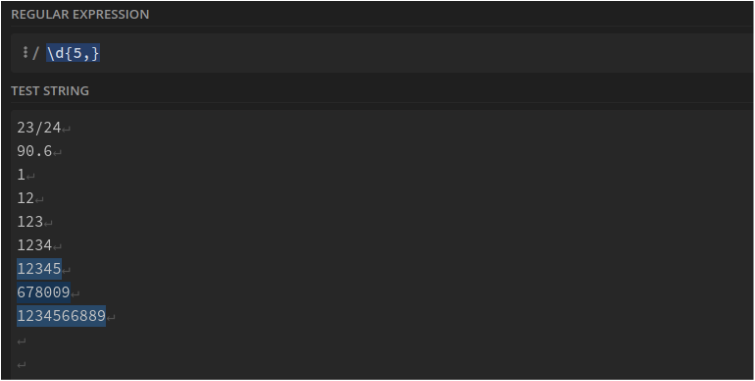
Nombre entier de 5 chiffres minimum : \d{5,}
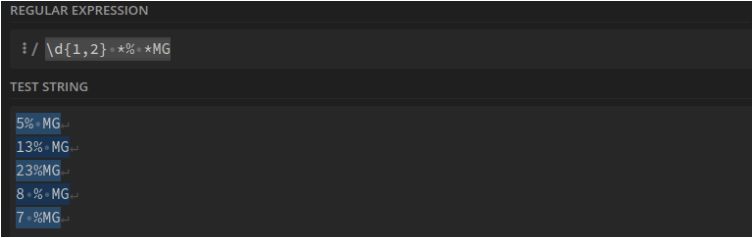
Pourcentage de matières grasses : \d{1,2} *% *MG
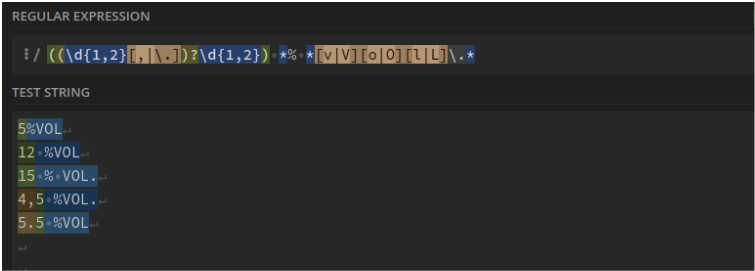
Degré d'alcool : ((\d{1,2}[,|.])?\d{1,2}) *% *[v|V][o|O][l|L].*
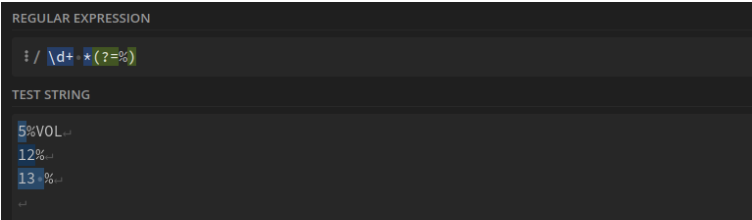
Nombre entier avant le symbole "%" : \d+ *(?=%)
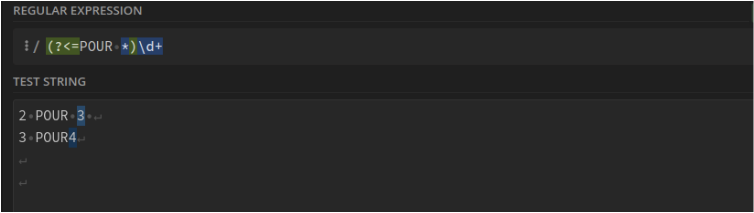
Nombre entier après le mot "POUR" : (?<=POUR *)\d+
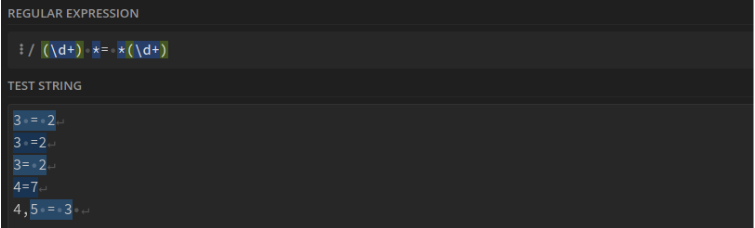
Égalité type 3 = 2 ou 3=2 : (\d+) *= *(\d+)
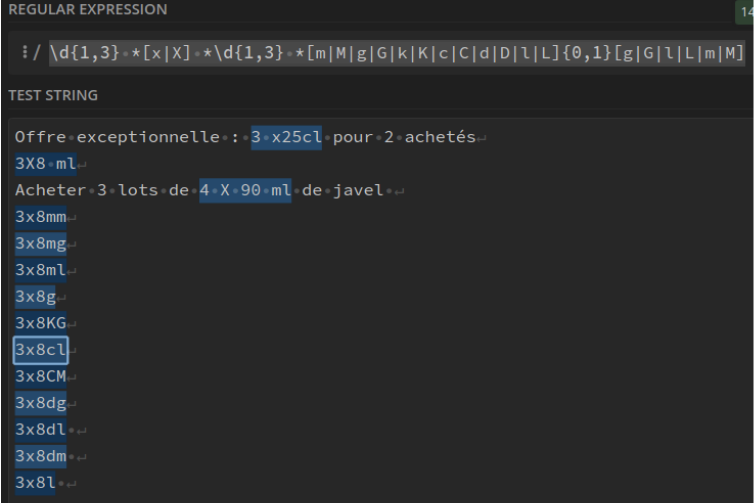
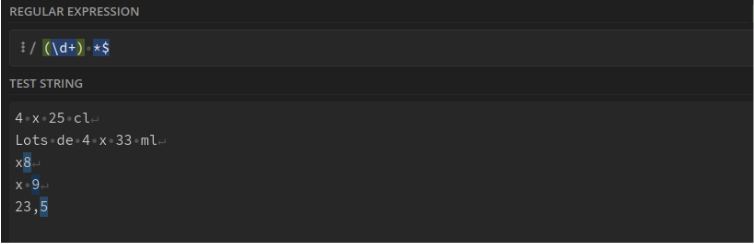
Lots. Ex : 6 x 25 cl : \d{1,3} *[x|X] *\d{1,3} *[m|M|g|G|k|K|c|C|d|D|l|L]{0,1}[g|G|l|L|m|M]
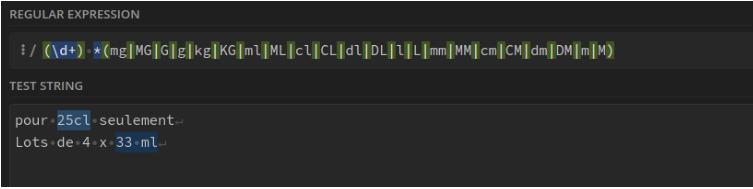
Contenance seule. Ex : 75cl : (\d+) *(mg|MG|G|g|kg|KG|ml|ML|cl|CL|dl|DL|l|L|mm|MM|cm|CM|dm|DM|m|M)
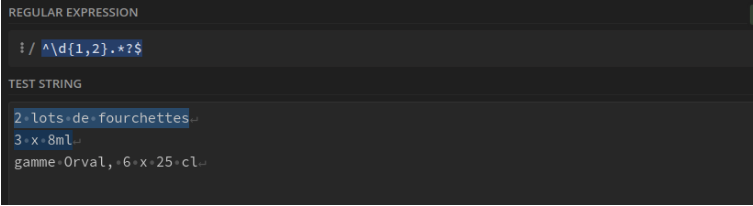
Nombre à 1 ou 2 chiffres en début de ligne et tout ce qui le suit : ^\d{1,2}.*?$
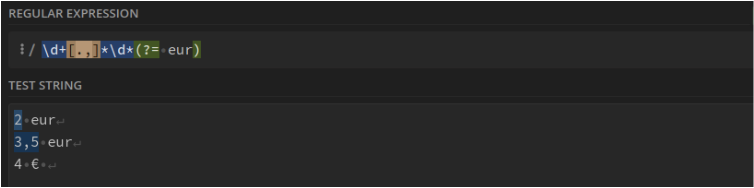
Le prix en euros mais sans la monnaie. Ex : 132,45 : \d+[.,]*\d*(?= eur)
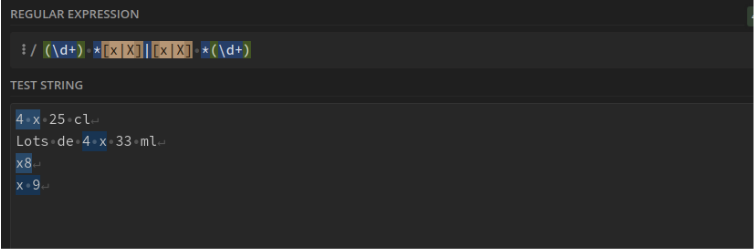
Nombre suivi ou précédé d'un "x" dans une expression de lot. Ex : "6 x 25 cl" renvoie "6 x" et "x7" renvoie "x7" : (\d+) *[x|X]|[x|X] *(\d+)
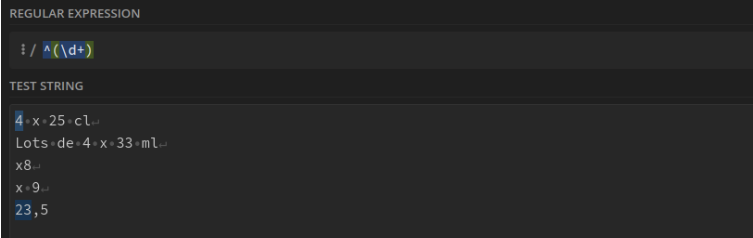
Premier nombre entier d'une ligne : ^(\d+)
Dernier nombre entier d'une ligne : (\d+) *$
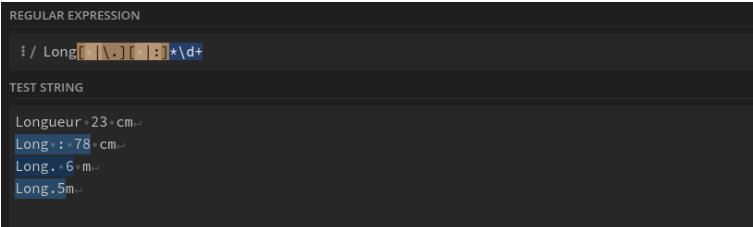
“Long” avec nombre entier. Le point, l'espace et les deux points entre eux sont optionnels : Long[ |\.][ |:]*\d+
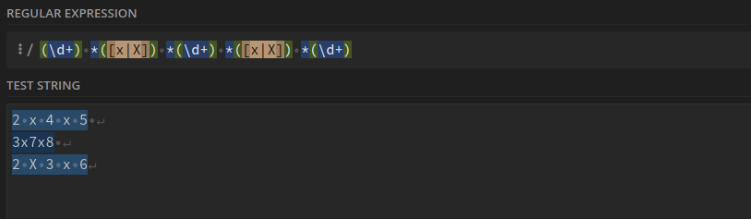
Longueur x largeur x hauteur : (\d+) *([x|X]) *(\d+) *([x|X]) *(\d+)
# Les dates
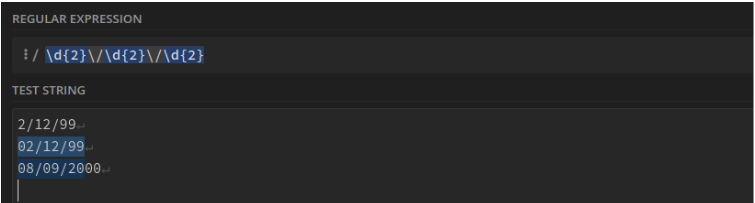
Date au format JJ/MM/AA : \d{2}\/\d{2}\/\d{2}
# Les caractères spécifiques
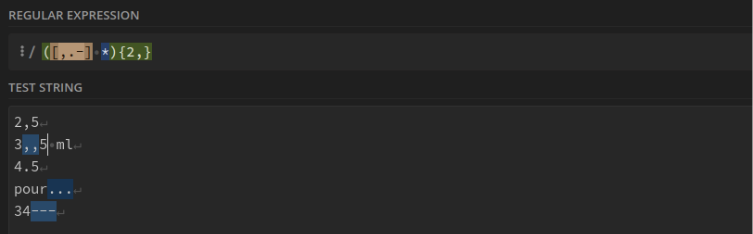
Les points, virgules et tirets répétés deux fois ou plus : ([,.-] *){2,}
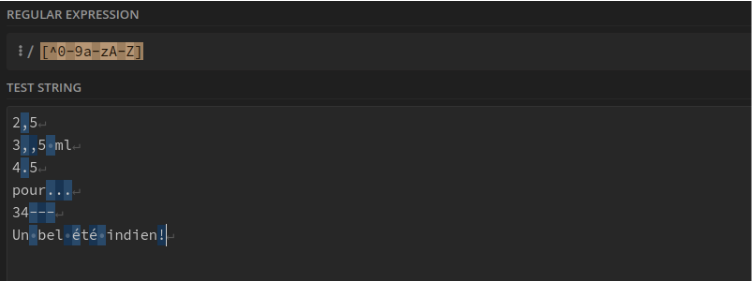
Tout ce qui n'est pas un chiffre, une minuscule ou une majuscule non accentuée : [^0-9a-zA-Z]
# Web
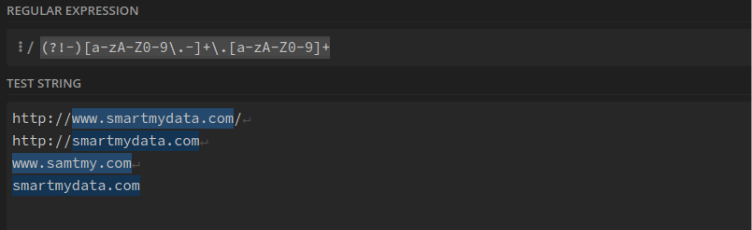
Nom de domaine : (?!-)[a-zA-Z0-9\.-]+\.[a-zA-Z0-9]+
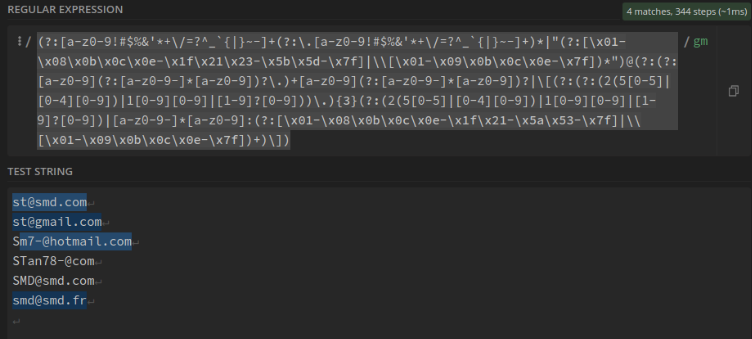
Adresse mail :

# Autres recherches
Chaîne vide : $^
Trois lettres minuscules suivies d'un nombre de deux chiffres minimum. Ex : trp12 : [a-z]{3}\d{2,}
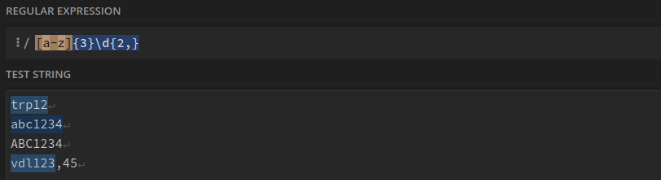
Deux lettres minuscules suivies d'un "-" puis d'un nombre de 4 chiffres minimum. Ex : tr-1234 : [a-z]{2}-\d{4,}
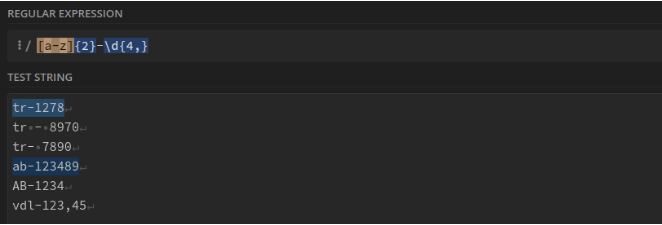
Deux minuscules suivies de 5 chiffres, d'un tiret, de trois minuscules, d'un tiret et d'un chiffre. Ex : tr12234-ret-1 : [a-z]{2}\d{5}-[a-z]{3}-\d
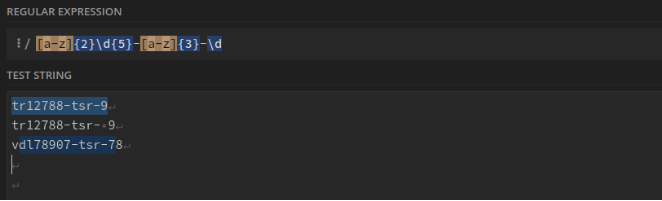
Les guillemets et tout ce qui est entre eux. Ex : "12h45" : "(.*?)"
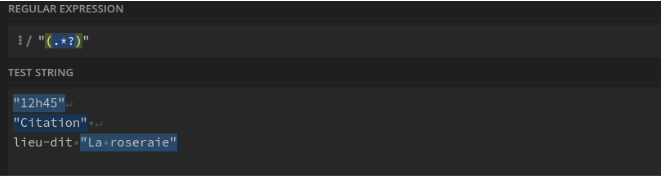
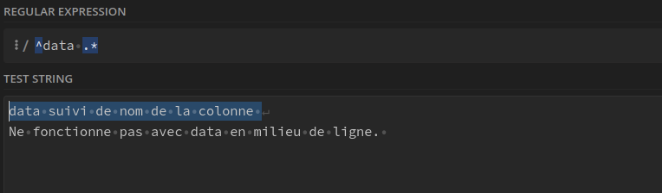
data et tout ce qui suit, à condition que data soit en début de ligne. : ^data .*
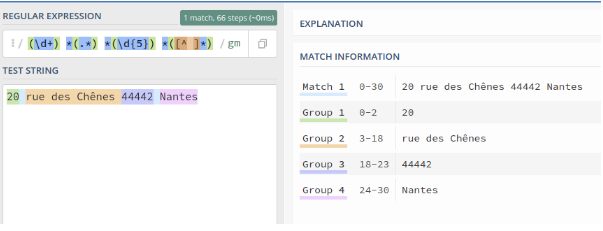
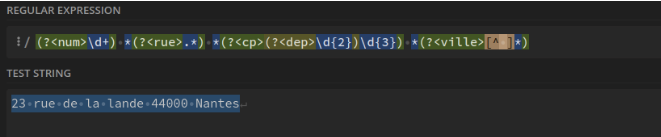
Tous les éléments d'une adresse : numéro, rue, cp et ville : (?<num>\d+) *(?<rue>.*) *(?<cp>(?<dep>\d{2})\d{3}) *(?<ville>[^ ]*) Ici, les expressions sont récupérées par groupes classés par leurs noms.
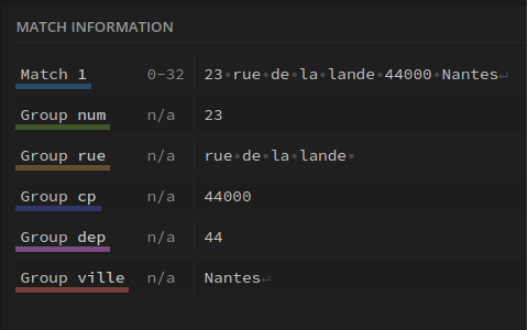
Tout se qui est entre les deux bornes, ici les expressions "Magasin de livraison différente | " et " | Mode de paiement : (?<=Magasin de livraison différente \| ).*(?= \| Mode de paiement)
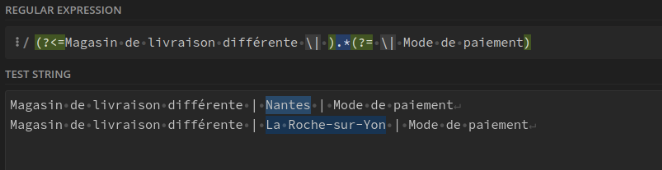
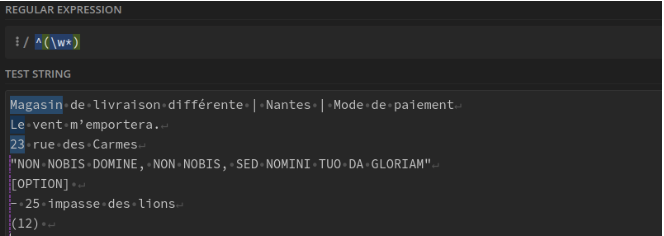
La première expression alphanumérique de la chaîne de caractères : ^(\w*)
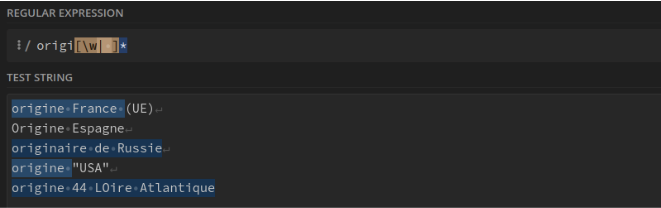
Tous les caractères alphanumériques et les espaces après "origi" jusqu’à la fin de ligne ou rencontrer un caractère non alphanumérique (ponctuation par ex) : origi[\w| ]*
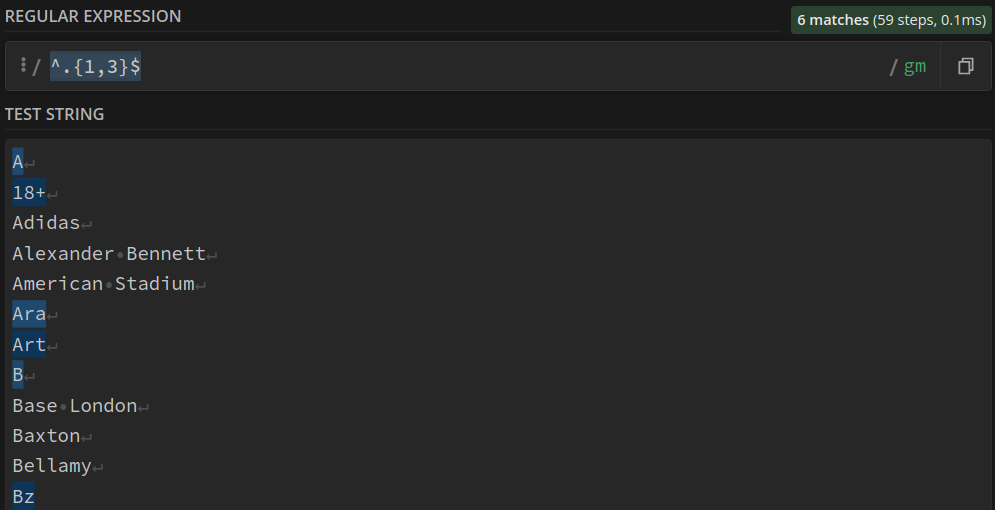
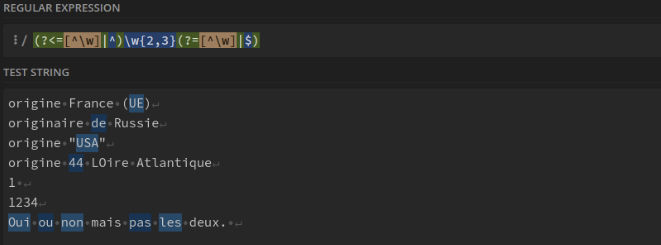
Toutes les expressions de 2 ou 3 caractères : (?<=[^\w]|^)\w{2,3}(?=[^\w]|$)
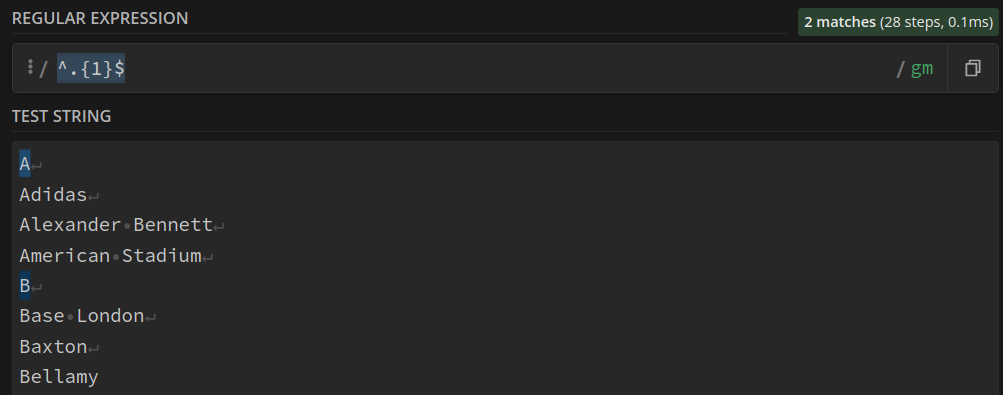
Les expressions ne contenant qu’une seule lettre : ^.{1}$
Les expressions contenant moins de 4 lettres : ^.{1,3}$